The post MinervaDB Webinar – Building MySQL Database Infrastructure for Performance and Reliability appeared first on The WebScale Database Infrastructure Operations Experts.
]]>Recently I did a webinar on ” Building MySQL Database Infrastructure for Performance and Reliability ” , It was big success and thought will share the slides of webinar in this blog. I get lot of emails daily from Database Architects, DBAs, Database Engineers, Technical Managers and Developers worldwide on best practices and checklist to build MySQL for performance, scalability, high availability and database SRE, The objective of this webinar is to share with them a cockpit view of MySQL infrastructure operations from MinervaDB perspective. Database Systems are growing faster than ever, The modern datanomy businesses like Facebook, Uber, Airbnb, LinkedIn etc. are powered by Database Systems, This makes Database Infrastructure operationally complex and we can’t technically scale such systems with eyeballs. Building MySQL operations for web-scale means delivering highly responsive, fault-tolerant and self-healing database infrastructure for business. In this webinar we are discussing following topics:
- Configuring MySQL for performance and reliability
- Troubleshooting MySQL with Linux tools
- Troubleshooting MySQL with slow query log
- Most common tools used in MinervaDB to troubleshoot MySQL performance
- Monitoring MySQL performance
- Building MySQL infrastructure operations for performance, scalability and reliability
- MySQL Replication
You can download PDF of the webinar here

The post MinervaDB Webinar – Building MySQL Database Infrastructure for Performance and Reliability appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Tuning MyRocks for performance appeared first on The WebScale Database Infrastructure Operations Experts.
]]>We know InnoDB is constrained by a fixed compressed page size. Alignment during fragmentation and compression causes extra unused space because the leaf nodes are not full. Let’s consider a InnoDB table with a compressed page size of 8KB. A 16KB in-memory page compressed to 5KB still uses 8KB on storage. Adding to this, each entry in the primary key index has 13 bytes of metadata (6 byte transaction id + 7 byte rollback pointer), and the metadata is not compressed, making the space overhead significant for small rows. Typically flash devices are limited by the WRITE endurance, In a typical scenario were index values are stored in leaf nodes and sorted by key, the often operational database may not fit in memory and keys get updated in an random platform leading to higher write amplification. In the worst case, updating one row requires a number of page reads, makes several pages dirty, and forces many dirty pages to be written back to storage.
Sow now what I really love about MyRocks?
It’s all about much lower write amplification factor of RocksDB compared to InnoDB is what I am very much impressed about. On pure flash, reducing write volume (write amplification) is important because flash burns out if writing too much data. Reducing write volume also helps to improve overall throughput on flash. InnoDB adopts “update in place” architecture. Even though updating just 1 record, an entire page where the row belongs becomes dirty, and the dirty page has to be written back to storage. On typical OLTP systems, modification unit (row) size is much smaller than I/O unit (page) size. This makes write amplification very high. I have published performance benchmarking of InnoDB, RocksDB and TokuDB, You can read about it here
Things to remember before tuning MyRocks:
- Data loading limitations
- Limitation – Transaction must fit in memory:
- mysql > ALTER TABLE post_master ENGINE = RocksDB;
- Error 2013 (HY000): Lost connection to MySQL server during query.
- Higher memory consumption and eventually get killed by OOM killer
- mysql > ALTER TABLE post_master ENGINE = RocksDB;
- When loading data into MyRocks tables, there are two recommended session variables:
- SET session sql_log_bin=0;
- SET session rocksdb_bulk_load=1;
- Limitation – Transaction must fit in memory:
There are few interesting things to remember before bulk loading MyRocks and tuning the system variable rocksdb_bulk_load:
- Data being bulk loaded can never overlap with existing data in the table. It is always recommended to bulk data load into an empty table. But, The mode will allow loading some data into the table, doing other operations and then returning and bulk loading addition data if there is no overlap between what is loaded and what already exists.
- The data may not be visible until the bulk load mode is ended (i.e. the rocksdb_bulk_load is set to zero again). RocksDB stores data into “SST” (Sorted String Table) files and Until a particular SST has been added the data will not be visible to the rest of the system, thus issuing a SELECT on the table currently being bulk loaded will only show older data and will likely not show the most recently added rows. Ending the bulk load mode will cause the most recent SST file to be added. When bulk loading multiple tables, starting a new table will trigger the code to add the most recent SST file to the system — as a result, it is inadvisable to interleave INSERT statements to two or more tables during bulk load mode.
Configuring MyRocks for performance:
Character Sets:
- MyRocks works more optimal with case sensitive collations (latin1_bin, utf8_bin, binary)
Transaction
- Read Committed isolation level is recommended. MyRocks’s transaction isolation implementation is different from InnoDB, but close to PostgreSQL. Default tx isolation in PostgreSQL is Read Committed.
Compression
- Set kNoCompression (or kLZ4Compression) on L0-1 or L0-2
- In the bottommost level, using stronger compression algorithm (Zlib or ZSTD) is recommended.
- If using zlib compression, set kZlibCompression at the bottommost level (bottommost_compression).
- If using zlib compression, set compression level accordingly. The above example (compression_opts=-14:1:0) uses zlib compression level 1. If your application is not write intensive, setting (compression_opts=-14:6:0) will give better space savings (using zlib compression level 6).
- For other levels, set kLZ4Compression.
Data blocks, files and compactions
- Set level_compaction_dynamic_level_bytes=true
- Set proper rocksdb_block_size (default 4096). Larger block size will reduce space but increase CPU overhead because MyRocks has to uncompress many more bytes. There is a trade-off between space and CPU usage.
- Set rocksdb_max_open_files=-1. If setting greater than 0, RocksDB still uses table_cache, which will lock a mutex every time you access the file. I think you’ll see much greater benefit with -1 because then you will not need to go through LRUCache to get the table you need.
- Set reasonable rocksdb_max_background_jobs
- Set not small target_file_size_base (32MB is generally sufficient). Default is 4MB, which is generally too small and creates too many sst files. Too many sst files makes operations more difficult.
- Set Rate Limiter. Without rate limiter, compaction very often writes 300~500MB/s on pure flash, which may cause short stalls. On 4x MyRocks testing, 40MB/s rate limiter per instance gave pretty stable results (less than 200MB/s peak from iostat).
Bloom Filter
- Configure bloom filter and Prefix Extractor. Full Filter is recommended (Block based filter does not work for Get() + prefix bloom). Prefix extractor can be configured per column family and uses the first prefix_extractor bits as the key. If using one BIGINT column as a primary key, recommended bloom filter size is 12 (first 4 bytes are for internal index id + 8 byte BIGINT).
- Configure Memtable bloom filter. Memtable bloom filter is useful to reduce CPU usage, if you see high CPU usage at rocksdb::MemTable::KeyComparator. Size depends on Memtable size. Set memtable_prefix_bloom_bits=41943040 for 128MB Memtable (30/128M=4M keys * 10 bits per key).
Cache
- Do not set block_cache at rocksdb_default_cf_options (block_based_table_factory). If you do provide a block cache size on a default column family, the same cache is NOT reused for all such column families.
- Consider setting shared write buffer size (db_write_buffer_size)
- Consider using compaction_pri=kMinOverlappingRatio for writing less on compaction.
Reference Source: https://github.com/facebook/mysql-5.6/wiki/my.cnf-tuning
The post Tuning MyRocks for performance appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Installation and configuration of Percona XtraDB Cluster on CentOS 7.3 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>This cluster will be assembled of three servers/nodes:
node #1 hostname: PXC1 IP: 138.197.70.35 node #2 hostname: PXC2 IP: 159.203.118.230 node #3 hostname: PXC3 IP: 138.197.8.226
Prerequisites
- All three nodes have a CentOS 7.3 installation.
- Firewall has been set up to allow connecting to ports 3306, 4444, 4567 and 4568
- SELinux is disabled
Installing from Percona Repository on 138.197.70.35
- Install the Percona repository package:
$ sudo yum install http://www.percona.com/downloads/percona-release/redhat/0.1-4/percona-release-0.1-4.noarch.rpm
- You should see the following if successful:
Installed: percona-release.noarch 0:0.1-4 Complete!
- Check that the packages are available:
$ sudo yum list | grep Percona-XtraDB-Cluster-57 Percona-XtraDB-Cluster-57.x86_64 5.7.14-26.17.1.el7 percona-release-x86_64 Percona-XtraDB-Cluster-57-debuginfo.x86_64 5.7.14-26.17.1.el7 percona-release-x86_64
- Install the Percona XtraDB Cluster packages:
$ sudo yum install Percona-XtraDB-Cluster-57
- Start the Percona XtraDB Cluster server:
$ sudo service mysql start
- Copy the automatically generated temporary password for the superuser account:
$ sudo grep 'temporary password' /var/log/mysqld.log
- Use this password to login as root:
$ mysql -u root -p
- Change the password for the superuser account and log out. For example:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'root'; Query OK, 0 rows affected (0.00 sec) mysql> exit Bye
- Stop the mysql service:
$ sudo service mysql stop
Repeat the same Percona XtraDB Cluster installation process for 159.203.118.230 and 138.197.8.226
Configuring nodes
We have to configure separately the nodes 138.197.70.35, 159.203.118.230 and 138.197.8.226 for successfully implementing an fully operational Percona XtraDB Cluster ecosystem.
Configuring the node 138.197.70.35
Configuration file /etc/my.cnf for the first node should look like:
[mysqld] datadir=/var/lib/mysql user=mysql # Path to Galera library wsrep_provider=/usr/lib64/libgalera_smm.so # Cluster connection URL contains the IPs of node#1, node#2 and node#3 wsrep_cluster_address=gcomm://138.197.70.35,159.203.118.230,138.197.8.226 # In order for Galera to work correctly binlog format should be ROW binlog_format=ROW # MyISAM storage engine has only experimental support default_storage_engine=InnoDB # This changes how InnoDB autoincrement locks are managed and is a requirement for Galera innodb_autoinc_lock_mode=2 # Node #1 address wsrep_node_address=138.197.70.35 # SST method wsrep_sst_method=xtrabackup-v2 # Cluster name wsrep_cluster_name=pxc_cluster # Authentication for SST method wsrep_sst_auth="sstuser:sstuser"
The first node can be started with the following command:
# /etc/init.d/mysql bootstrap-pxc
We are using CentOS 7.3 so systemd bootstrap service should be used:
# systemctl start mysql@bootstrap.service
This command will start the cluster with initial wsrep_cluster_address set to gcomm://. This way the cluster will be bootstrapped and in case the node or MySQL have to be restarted later, there would be no need to change the configuration file.
After the first node has been started, cluster status can be checked by:
mysql> show status like 'wsrep%'; +------------------------------+------------------------------------------------------------+ | Variable_name | Value | +------------------------------+------------------------------------------------------------+ | wsrep_local_state_uuid | 5ea977b8-0fc0-11e7-8f73-26f60f083bd5 | | wsrep_protocol_version | 7 | | wsrep_last_committed | 8 | | wsrep_replicated | 4 | | wsrep_replicated_bytes | 906 | | wsrep_repl_keys | 4 | | wsrep_repl_keys_bytes | 124 | | wsrep_repl_data_bytes | 526 | | wsrep_repl_other_bytes | 0 | | wsrep_received | 9 | | wsrep_received_bytes | 1181 | | wsrep_local_commits | 0 | | wsrep_local_cert_failures | 0 | | wsrep_local_replays | 0 | | wsrep_local_send_queue | 0 | | wsrep_local_send_queue_max | 1 | | wsrep_local_send_queue_min | 0 | | wsrep_local_send_queue_avg | 0.000000 | | wsrep_local_recv_queue | 0 | | wsrep_local_recv_queue_max | 2 | | wsrep_local_recv_queue_min | 0 | | wsrep_local_recv_queue_avg | 0.111111 | | wsrep_local_cached_downto | 3 | | wsrep_flow_control_paused_ns | 0 | | wsrep_flow_control_paused | 0.000000 | | wsrep_flow_control_sent | 0 | | wsrep_flow_control_recv | 0 | | wsrep_flow_control_interval | [ 28, 28 ] | | wsrep_cert_deps_distance | 1.000000 | | wsrep_apply_oooe | 0.000000 | | wsrep_apply_oool | 0.000000 | | wsrep_apply_window | 1.000000 | | wsrep_commit_oooe | 0.000000 | | wsrep_commit_oool | 0.000000 | | wsrep_commit_window | 1.000000 | | wsrep_local_state | 4 | | wsrep_local_state_comment | Synced | | wsrep_cert_index_size | 2 | | wsrep_cert_bucket_count | 22 | | wsrep_gcache_pool_size | 3128 | | wsrep_causal_reads | 0 | | wsrep_cert_interval | 0.000000 | | wsrep_incoming_addresses | 159.203.118.230:3306,138.197.8.226:3306,138.197.70.35:3306 | | wsrep_desync_count | 0 | | wsrep_evs_delayed | | | wsrep_evs_evict_list | | | wsrep_evs_repl_latency | 0/0/0/0/0 | | wsrep_evs_state | OPERATIONAL | | wsrep_gcomm_uuid | b79d90df-1077-11e7-9922-3a1b217f7371 | | wsrep_cluster_conf_id | 3 | | wsrep_cluster_size | 3 | | wsrep_cluster_state_uuid | 5ea977b8-0fc0-11e7-8f73-26f60f083bd5 | | wsrep_cluster_status | Primary | | wsrep_connected | ON | | wsrep_local_bf_aborts | 0 | | wsrep_local_index | 2 | | wsrep_provider_name | Galera | | wsrep_provider_vendor | Codership Oy <info@codership.com> | | wsrep_provider_version | 3.20(r7e383f7) | | wsrep_ready | ON | +------------------------------+------------------------------------------------------------+ 60 rows in set (0.01 sec)
This output above shows that the cluster has been successfully bootstrapped.
In order to perform successful State Snapshot Transfer using XtraBackup new user needs to be set up with proper privileges:
mysql@PXC1> CREATE USER 'sstuser'@'localhost' IDENTIFIED BY 'sstuser'; mysql@PXC1> GRANT PROCESS, RELOAD, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'sstuser'@'localhost'; mysql@PXC1> FLUSH PRIVILEGES;
Configuration file /etc/my.cnf on the second node (PXC2) should look like this:
[mysqld] datadir=/var/lib/mysql user=mysql # Path to Galera library wsrep_provider=/usr/lib64/libgalera_smm.so # Cluster connection URL contains the IPs of node#1, node#2 and node#3 wsrep_cluster_address=gcomm://138.197.70.35,159.203.118.230,138.197.8.226 # In order for Galera to work correctly binlog format should be ROW binlog_format=ROW # MyISAM storage engine has only experimental support default_storage_engine=InnoDB # This changes how InnoDB autoincrement locks are managed and is a requirement for Galera innodb_autoinc_lock_mode=2 # Node #2 address wsrep_node_address=159.203.118.230 # SST method wsrep_sst_method=xtrabackup-v2 # Cluster name wsrep_cluster_name=pxc_cluster # Authentication for SST method wsrep_sst_auth="sstuser:sstuser"
Second node can be started with the following command:
# systemctl start mysql
Cluster status can now be checked on both nodes. This is the example from the second node (PXC2):
mysql> show status like 'wsrep%'; +------------------------------+------------------------------------------------------------+ | Variable_name | Value | +------------------------------+------------------------------------------------------------+ | wsrep_local_state_uuid | 5ea977b8-0fc0-11e7-8f73-26f60f083bd5 | | wsrep_protocol_version | 7 | | wsrep_last_committed | 8 | | wsrep_replicated | 0 | | wsrep_replicated_bytes | 0 | | wsrep_repl_keys | 0 | | wsrep_repl_keys_bytes | 0 | | wsrep_repl_data_bytes | 0 | | wsrep_repl_other_bytes | 0 | | wsrep_received | 10 | | wsrep_received_bytes | 1238 | | wsrep_local_commits | 0 | | wsrep_local_cert_failures | 0 | | wsrep_local_replays | 0 | | wsrep_local_send_queue | 0 | | wsrep_local_send_queue_max | 1 | | wsrep_local_send_queue_min | 0 | | wsrep_local_send_queue_avg | 0.000000 | | wsrep_local_recv_queue | 0 | | wsrep_local_recv_queue_max | 1 | | wsrep_local_recv_queue_min | 0 | | wsrep_local_recv_queue_avg | 0.000000 | | wsrep_local_cached_downto | 6 | | wsrep_flow_control_paused_ns | 0 | | wsrep_flow_control_paused | 0.000000 | | wsrep_flow_control_sent | 0 | | wsrep_flow_control_recv | 0 | | wsrep_flow_control_interval | [ 28, 28 ] | | wsrep_cert_deps_distance | 1.000000 | | wsrep_apply_oooe | 0.000000 | | wsrep_apply_oool | 0.000000 | | wsrep_apply_window | 1.000000 | | wsrep_commit_oooe | 0.000000 | | wsrep_commit_oool | 0.000000 | | wsrep_commit_window | 1.000000 | | wsrep_local_state | 4 | | wsrep_local_state_comment | Synced | | wsrep_cert_index_size | 2 | | wsrep_cert_bucket_count | 22 | | wsrep_gcache_pool_size | 2300 | | wsrep_causal_reads | 0 | | wsrep_cert_interval | 0.000000 | | wsrep_incoming_addresses | 159.203.118.230:3306,138.197.8.226:3306,138.197.70.35:3306 | | wsrep_desync_count | 0 | | wsrep_evs_delayed | | | wsrep_evs_evict_list | | | wsrep_evs_repl_latency | 0/0/0/0/0 | | wsrep_evs_state | OPERATIONAL | | wsrep_gcomm_uuid | 248e2782-1078-11e7-a269-4a3ec033a606 | | wsrep_cluster_conf_id | 3 | | wsrep_cluster_size | 3 | | wsrep_cluster_state_uuid | 5ea977b8-0fc0-11e7-8f73-26f60f083bd5 | | wsrep_cluster_status | Primary | | wsrep_connected | ON | | wsrep_local_bf_aborts | 0 | | wsrep_local_index | 0 | | wsrep_provider_name | Galera | | wsrep_provider_vendor | Codership Oy <info@codership.com> | | wsrep_provider_version | 3.20(r7e383f7) | | wsrep_ready | ON | +------------------------------+------------------------------------------------------------+ 60 rows in set (0.00 sec)
This output shows that the new node has been successfully added to the cluster.
MySQL configuration file /etc/my.cnf on the third node (PXC3) should look like this:
[mysqld] datadir=/var/lib/mysql user=mysql # Path to Galera library wsrep_provider=/usr/lib64/libgalera_smm.so # Cluster connection URL contains the IPs of node#1, node#2 and node#3 wsrep_cluster_address=gcomm://138.197.70.35,159.203.118.230,138.197.8.226 # In order for Galera to work correctly binlog format should be ROW binlog_format=ROW # MyISAM storage engine has only experimental support default_storage_engine=InnoDB # This changes how InnoDB autoincrement locks are managed and is a requirement for Galera innodb_autoinc_lock_mode=2 # Node #3 address wsrep_node_address=138.197.8.226 # SST method wsrep_sst_method=xtrabackup-v2 # Cluster name wsrep_cluster_name=pxc_cluster # Authentication for SST method wsrep_sst_auth="sstuser:sstuser"
Third node can now be started with the following command:
# systemctl start mysql
Percona XtraDB Cluster status can now be checked from the third node (PXC3):
mysql> show status like 'wsrep%'; +------------------------------+------------------------------------------------------------+ | Variable_name | Value | +------------------------------+------------------------------------------------------------+ | wsrep_local_state_uuid | 5ea977b8-0fc0-11e7-8f73-26f60f083bd5 | | wsrep_protocol_version | 7 | | wsrep_last_committed | 8 | | wsrep_replicated | 2 | | wsrep_replicated_bytes | 396 | | wsrep_repl_keys | 2 | | wsrep_repl_keys_bytes | 62 | | wsrep_repl_data_bytes | 206 | | wsrep_repl_other_bytes | 0 | | wsrep_received | 4 | | wsrep_received_bytes | 529 | | wsrep_local_commits | 0 | | wsrep_local_cert_failures | 0 | | wsrep_local_replays | 0 | | wsrep_local_send_queue | 0 | | wsrep_local_send_queue_max | 1 | | wsrep_local_send_queue_min | 0 | | wsrep_local_send_queue_avg | 0.000000 | | wsrep_local_recv_queue | 0 | | wsrep_local_recv_queue_max | 1 | | wsrep_local_recv_queue_min | 0 | | wsrep_local_recv_queue_avg | 0.000000 | | wsrep_local_cached_downto | 6 | | wsrep_flow_control_paused_ns | 0 | | wsrep_flow_control_paused | 0.000000 | | wsrep_flow_control_sent | 0 | | wsrep_flow_control_recv | 0 | | wsrep_flow_control_interval | [ 28, 28 ] | | wsrep_cert_deps_distance | 1.000000 | | wsrep_apply_oooe | 0.000000 | | wsrep_apply_oool | 0.000000 | | wsrep_apply_window | 1.000000 | | wsrep_commit_oooe | 0.000000 | | wsrep_commit_oool | 0.000000 | | wsrep_commit_window | 1.000000 | | wsrep_local_state | 4 | | wsrep_local_state_comment | Synced | | wsrep_cert_index_size | 2 | | wsrep_cert_bucket_count | 22 | | wsrep_gcache_pool_size | 2166 | | wsrep_causal_reads | 0 | | wsrep_cert_interval | 0.000000 | | wsrep_incoming_addresses | 159.203.118.230:3306,138.197.8.226:3306,138.197.70.35:3306 | | wsrep_desync_count | 0 | | wsrep_evs_delayed | | | wsrep_evs_evict_list | | | wsrep_evs_repl_latency | 0/0/0/0/0 | | wsrep_evs_state | OPERATIONAL | | wsrep_gcomm_uuid | 3f51b20e-1078-11e7-8405-8e9b37a37cb1 | | wsrep_cluster_conf_id | 3 | | wsrep_cluster_size | 3 | | wsrep_cluster_state_uuid | 5ea977b8-0fc0-11e7-8f73-26f60f083bd5 | | wsrep_cluster_status | Primary | | wsrep_connected | ON | | wsrep_local_bf_aborts | 0 | | wsrep_local_index | 1 | | wsrep_provider_name | Galera | | wsrep_provider_vendor | Codership Oy <info@codership.com> | | wsrep_provider_version | 3.20(r7e383f7) | | wsrep_ready | ON | +------------------------------+------------------------------------------------------------+ 60 rows in set (0.03 sec)
This output confirms that the third node has joined the cluster.
Testing Replication
Creating the new database on the PXC1 node:
mysql> create database minervadb; Query OK, 1 row affected (0.01 sec)
Creating the example table on the PXC2 node:
mysql> use minervadb; Database changed mysql> CREATE TABLE example (node_id INT PRIMARY KEY, node_name VARCHAR(30)); Query OK, 0 rows affected (0.01 sec)
Inserting records on the PXC3 node:
mysql> INSERT INTO minervadb.example VALUES (1, 'MinervaDB'); Query OK, 1 row affected (0.07 sec)
Retrieving all the rows from that table on the PXC1 node:
mysql> select * from minervadb.example; +---------+-----------+ | node_id | node_name | +---------+-----------+ | 1 | MinervaDB | +---------+-----------+ 1 row in set (0.00 sec)
The post Installation and configuration of Percona XtraDB Cluster on CentOS 7.3 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post What is MySQL partitioning ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>CREATE TABLE tab1 (
col1 VARCHAR(30) NOT NULL,
col2 VARCHAR(30) NOT NULL,
col3 TINYINT UNSIGNED NOT NULL,
col4 DATE NOT NULL
)
PARTITION BY RANGE( col3 ) (
PARTITION p0 VALUES LESS THAN (100),
PARTITION p1 VALUES LESS THAN (200),
PARTITION p2 VALUES LESS THAN (300),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
Write a SELECT query benefitting partition pruning:
SELECT col1, col2, col3, col4 FROM tab1 WHERE col3 > 200 AND col3 < 250;
What is explicit partitioning in MySQL and how is it different from partition pruning ?
In MySQL we can explicitly select partition and sub-partitions when executing a statement matching a given WHERE condition, This sounds very much similar to partition pruning, but there is a difference:
- Partition to be checked are explicitly mentioned in the query statement, In partition pruning it is automatic.
- In explicit partition, the explicit selection of partitions is supported for both queries and DML statements, partition pruning applies only to queries.
- SQL statements supported in explicit partitioning – SELECT, INSERT, UPDATE, DELETE, LOAD DATA, LOAD XML and REPLACE
Explicit partition example:
CREATE TABLE customer (
cust_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
cust_fname VARCHAR(25) NOT NULL,
cust_lname VARCHAR(25) NOT NULL,
cust_phone INT NOT NULL,
cust_fax INT NOT NULL
)
PARTITION BY RANGE(cust_id) (
PARTITION p0 VALUES LESS THAN (100),
PARTITION p1 VALUES LESS THAN (200),
PARTITION p2 VALUES LESS THAN (300),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
Query explicitly mentioning partition:
mysql> SELECT * FROM customer PARTITION (p1);
RANGE partitioning
In RANGE partitioning you can partition values within a given range, Ranges should be contiguous but not overlapping, usually defined by VALUES LESS THAN operator, The following examples explain how to create and use RANGE partitioning for MySQL performance:
CREATE TABLE customer_contract(
cust_id INT NOT NULL,
cust_fname VARCHAR(30),
cust_lname VARCHAR(30),
st_dt DATE NOT NULL DEFAULT '1970-01-01',
end_dt DATE NOT NULL DEFAULT '9999-12-31',
contract_code INT NOT NULL,
contract_id INT NOT NULL
)
PARTITION BY RANGE (contract_id) (
PARTITION p0 VALUES LESS THAN (50),
PARTITION p1 VALUES LESS THAN (100),
PARTITION p2 VALUES LESS THAN (150),
PARTITION p3 VALUES LESS THAN (200)
);
For example, let us suppose that you wish to partition based on the year contract ended:
CREATE TABLE customer_contract(
cust_id INT NOT NULL,
cust_fname VARCHAR(30),
cust_lname VARCHAR(30),
st_dt DATE NOT NULL DEFAULT '1970-01-01',
end_dt DATE NOT NULL DEFAULT '9999-12-31',
contract_code INT NOT NULL,
contract_id INT NOT NULL
)
PARTITION BY RANGE (year(end_dt)) (
PARTITION p0 VALUES LESS THAN (2001),
PARTITION p1 VALUES LESS THAN (2002),
PARTITION p2 VALUES LESS THAN (2003),
PARTITION p3 VALUES LESS THAN (2004)
);
It is also possible to partition a table by RANGE, based on the value of a TIMESTAMP column, using the UNIX_TIMESTAMP() function, as shown in this example:
CREATE TABLE sales_forecast (
sales_forecast_id INT NOT NULL,
sales_forecast_status VARCHAR(20) NOT NULL,
sales_forecast_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(sales_forecast_updated) ) (
PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ),
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ),
PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ),
PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ),
PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ),
PARTITION p9 VALUES LESS THAN (MAXVALUE)
);
LIST partitioning
The difference between RANGE and LIST partitioning is: In LIST partitioning, each partition is grouped on the selected list of values of a specific column. You can do it by PARTITION BY LIST (EXPR) where EXPR is the selected column for list partition, We have explained LIST partitioning with example below:
CREATE TABLE students (
student_id INT NOT NULL,
student_fname VARCHAR(30),
student_lname VARCHAR(30),
student_joined DATE NOT NULL DEFAULT '1970-01-01',
student_separated DATE NOT NULL DEFAULT '9999-12-31',
student_house INT,
student_grade_id INT
)
PARTITION BY LIST(student_grade_id) (
PARTITION P1 VALUES IN (1,2,3,4),
PARTITION P2 VALUES IN (5,6,7),
PARTITION P3 VALUES IN (8,9,10),
PARTITION P4 VALUES IN (11,12)
);
HASH partitioning
HASH partitioning makes an even distribution of data among predetermined number of partitions, In RANGE and LIST partitioning you must explicitly define the partitioning logic and which partition given column value or set of column values are stored. In HASH partitioning MySQL take care of this, The following example explains HASH partitioning better:
CREATE TABLE store (
store_id INT NOT NULL,
store_name VARCHAR(30),
store_location VARCHAR(30),
store_started DATE NOT NULL DEFAULT '1997-01-01',
store_code INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4;
P.S. : If you do not include a PARTITIONS clause, the number of partitions defaults to 1.
LINEAR HASH partitioning
The LINEAR HASH partitioning utilizes a linear powers-of-two algorithm, Where HASH partitioning employs the modulus of the hashing function’s value. Please find below LINEAR HASH partitioning example:
CREATE TABLE store (
store_id INT NOT NULL,
store_name VARCHAR(30),
store_location VARCHAR(30),
store_started DATE NOT NULL DEFAULT '1997-01-01',
store_code INT
)
PARTITION BY LINEAR HASH( YEAR(store_started) )
PARTITIONS 4;
KEY partitioning
KEY partitioning is very much similar to HASH, the only difference is, the hashing function for the KEY partitioning is supplied by MySQL, In case of MySQL NDB Cluster, MD5() is used, For tables using other storage engines, the MySQL server uses the storage engine specific hashing function which is based on the same algorithm as PASSWORD().
CREATE TABLE contact(
id INT NOT NULL,
name VARCHAR(20),
contact_number INT,
email VARCHAR(50),
UNIQUE KEY (id)
)
PARTITION BY KEY()
PARTITIONS 5;
P.S. – if the unique key column were not defined as NOT NULL, then the previous statement would fail.
Subpartitioning
SUBPARTITIONING is also known as composite partitioning, You can partition table combining RANGE and HASH for better results, The example below explains SUBPARTITIONING better:
CREATE TABLE purchase (id INT, item VARCHAR(30), purchase_date DATE)
PARTITION BY RANGE( YEAR(purchase_date) )
SUBPARTITION BY HASH( TO_DAYS(purchase_date) )
SUBPARTITIONS 2 (
PARTITION p0 VALUES LESS THAN (2000),
PARTITION p1 VALUES LESS THAN (2010),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
It is also possible to define subpartitions explicitly using SUBPARTITION clauses to specify options for individual subpartitions:
CREATE TABLE purchase (id INT, item VARCHAR(30), purchase_date DATE)
PARTITION BY RANGE( YEAR(purchase_date) )
SUBPARTITION BY HASH( TO_DAYS(purchase_date) ) (
PARTITION p0 VALUES LESS THAN (2000) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2010) (
SUBPARTITION s2,
SUBPARTITION s3
),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);
Things to remember:
- Each partition must have the same number of subpartitions.
- Each SUBPARTITION clause must include (at a minimum) a name for the subpartition. Otherwise, you may set any desired option for the subpartition or allow it to assume its default setting for that option.
- Subpartition names must be unique across the entire table. For example, the following CREATE TABLE statement is valid in MySQL 5.7:
CREATE TABLE purchase (id INT, item VARCHAR(30), purchase_date DATE)
PARTITION BY RANGE( YEAR(purchase_date) )
SUBPARTITION BY HASH( TO_DAYS(purchase_date) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000) (
SUBPARTITION s2,
SUBPARTITION s3
),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);
MySQL partitioning limitations
MySQL partitioning also has limitations, We are listing down below the limitations of MySQL partitioning:
A PRIMARY KEY must include all columns in the table’s partitioning function:
CREATE TABLE tab3 ( column1 INT NOT NULL, column2 DATE NOT NULL, column3 INT NOT NULL, column4 INT NOT NULL, UNIQUE KEY (column1, column2), UNIQUE KEY (column3) ) PARTITION BY HASH(column1 + column3) PARTITIONS 4;
Expect this error after running above script – ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table’s partitioning function
The right way of doing it:
CREATE TABLE table12 (
column1 INT NOT NULL,
column2 DATE NOT NULL,
column3 INT NOT NULL,
column4 INT NOT NULL,
UNIQUE KEY (column1, column2, column3)
)
PARTITION BY HASH(column3)
PARTITIONS 5;
CREATE TABLE table25 (
column11 INT NOT NULL,
column12 DATE NOT NULL,
column13 INT NOT NULL,
column14 INT NOT NULL,
UNIQUE KEY (column11, column13)
)
PARTITION BY HASH(column11 + column13)
PARTITIONS 5;
Most popular limitation of MySQL – Primary key is by definition a unique key, this restriction also includes the table’s primary key, if it has one. The example below explains this limitation better:
CREATE TABLE table55 (
column11 INT NOT NULL,
column12 DATE NOT NULL,
column13 INT NOT NULL,
column14 INT NOT NULL,
PRIMARY KEY(column11, column12)
)
PARTITION BY HASH(column13)
PARTITIONS 4;
CREATE TABLE table65 (
column20 INT NOT NULL,
column25 DATE NOT NULL,
column30 INT NOT NULL,
column35 INT NOT NULL,
PRIMARY KEY(column20, column30),
UNIQUE KEY(column25)
)
PARTITION BY HASH( YEAR(column25) )
PARTITIONS 5;
Both of the above scripts will return this error – ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table’s partitioning function
The right way of doing it:
CREATE TABLE t45 (
column50 INT NOT NULL,
column55 DATE NOT NULL,
column60 INT NOT NULL,
column65 INT NOT NULL,
PRIMARY KEY(column50, column55)
)
PARTITION BY HASH(column50 + YEAR(column55))
PARTITIONS 5;
CREATE TABLE table88 (
column80 INT NOT NULL,
column81 DATE NOT NULL,
column82 INT NOT NULL,
column83 INT NOT NULL,
PRIMARY KEY(column80, column81, column82),
UNIQUE KEY(column81, column82)
);
In above example, the primary key does not include all columns referenced in the partitioning expression. However, both of the statements are valid !
You can still successfully partition a MySQL table without unique keys – this also includes having no primary key and you may use any column or columns in the partitioning expression as long as the column type is compatible with the partitioning type, The example below shows partitioning a table with no unique / primary keys:
CREATE TABLE table_has_no_pk (column10 INT, column11 INT, column12 varchar(20)) PARTITION BY RANGE(column10) ( PARTITION p0 VALUES LESS THAN (500), PARTITION p1 VALUES LESS THAN (600), PARTITION p2 VALUES LESS THAN (700), PARTITION p3 VALUES LESS THAN (800) );
You cannot later add a unique key to a partitioned table unless the key includes all columns used by the table’s partitioning expression, The example below explains this much better:
ALTER TABLE table_has_no_pk ADD PRIMARY KEY(column10);
ALTER TABLE table_has_no_pk drop primary key;
ALTER TABLE table_has_no_pk ADD PRIMARY KEY(column10,column11);
ALTER TABLE table_has_no_pk drop primary key;
However, the next statement fails, because column10 is part of the partitioning key, but is not part of the proposed primary key:
mysql> ALTER TABLE table_has_no_pk ADD PRIMARY KEY(column11); ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function mysql>
MySQL partitioning limitations (at storage engine level)
InnoDB
- InnoDB foreign keys and MySQL partitioning are not compatible, Partitioned InnoDB tables cannot have foreign key references, nor can they have columns referenced by foreign keys, So you cannot partition InnoDB tables which have or referenced by foreign keys.
- InnoDB does not support use of multiple disks for subpartition (MyISAM supports this feature)
- Use ALTER TABLE … REBUILD PARTITION and ALTER TABLE … ANALYZE PARTITION than using ALTER TABLE … OPTIMIZE PARTITION
NDB storage engine
- We can only partition by KEY (including LINEAR KEY) in NDB storage engine.
FEDERATED storage engine
- Partitioning not supported in FEDERATED storage engine.
CSV storage engine
- Partitioning not supported in CSV storage engine.
MERGE storage engine
- Tables using the MERGE storage engine cannot be partitioned. Partitioned tables cannot be merged.
MySQL functions shown in the following list are allowed in partitioning expressions:
- ABS()
- CEILING()
- DATEDIFF()
- DAY()
- DAYOFMONTH()
- DAYOFWEEK()
- DAYOFYEAR()
- EXTRACT()
- FLOOR()
- HOUR()
- MICROSECOND()
- MINUTE()
- MOD()
- MONTH()
- QUARTER()
- SECOND()
- TIME_TO_SEC()
- TO_DAYS()
- TO_SECONDS()
- UNIX_TIMESTAMP()
- WEEKDAY()
- YEAR()
- YEARWEEK()
MySQL partitioning and locks
Effect on DML statements
- In MySQL 5.7, updating a partitioned MyISAM table cause only the affected partitioned to be locked.
- SELECT statements (including those containing unions or joins) lock only those partitions that actually need to be read. This also applies to SELECT …PARTITION.
- An UPDATE prunes locks only for tables on which no partitioning columns are updated.
- REPLACE and INSERT lock only those partitions having rows to be inserted or replaced. However, if an AUTO_INCREMENT value is generated for any partitioning column then all partitions are locked.
- INSERT … ON DUPLICATE KEY UPDATE is pruned as long as no partitioning column is updated.
- INSERT … SELECT locks only those partitions in the source table that need to be read, although all partitions in the target table are locked.
- Locks imposed by LOAD DATA statements on partitioned tables cannot be pruned.
Effect on DML statements
- CREATE VIEW does not cause any locks.
- ALTER TABLE … EXCHANGE PARTITION prunes locks; only the exchanged table and the exchanged partition are locked.
- ALTER TABLE … TRUNCATE PARTITION prunes locks; only the partitions to be emptied are locked.
- In addition, ALTER TABLE statements take metadata locks on the table level.
Effect on other statements
- LOCK TABLES cannot prune partition locks.
- CALL stored_procedure(expr) supports lock pruning, but evaluating expr does not.
- DO and SET statements do not support partitioning lock pruning.
The post What is MySQL partitioning ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post How to use mysqlpump for faster MySQL logical backup ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>- Supports parallel MySQL logical backup, The resource usage efficiency and high performance backups (we love it !)
- Much better orchestration possible – You can backup selected databases, tables, stored programs and user accounts etc.
- By default mysqlpump will not backup performance_schema, sys schema, ndbinfo by default, You have to name them with –databases or –include-databases option
- mysqlpump does not dump INFORMATION_SCHEMA schema.
- Faster secondary indexes creation, The indexes created only after inserting rows !
mysqlpump examples
Plain simple backup using mysqlpump:
[root@localhost mysqlpump2018-06-23-25-49]# mysqlpump -u root -p employees > employeebakup$(date '+%Y-%m-%H-%M-%S').sql Enter password: Dump progress: 1/4 tables, 0/630999 rows Dump progress: 2/6 tables, 541250/3919384 rows Dump progress: 4/6 tables, 1306627/3919384 rows Dump progress: 5/6 tables, 2128435/3919384 rows Dump progress: 5/6 tables, 3081685/3919384 rows Dump completed in 5309 milliseconds [root@localhost mysqlpump2018-06-23-25-49]#
Using mysqlpump based backup with 6 threads:
[root@localhost mysqlpump2018-06-23-25-49]# mysqlpump -u root -p employees --default-parallelism=6 > employeebakup$(date '+%Y-%m-%H-%M-%S').sql Enter password: Dump progress: 0/5 tables, 250/3477363 rows Dump progress: 2/6 tables, 606250/3919384 rows Dump progress: 3/6 tables, 1272103/3919384 rows Dump progress: 5/6 tables, 2028185/3919384 rows Dump progress: 5/6 tables, 2932185/3919384 rows Dump progress: 5/6 tables, 3864185/3919384 rows Dump completed in 5503 milliseconds [root@localhost mysqlpump2018-06-23-25-49]#
Using mysqlpump to backup only selected databases, spawned 5 threads to backup employee and sakila database:
[root@localhost mysqlpump2018-06-23-25-49]# mysqlpump -u root -p employees --parallel-schemas=5:employees,sakila --default-parallelism=6 > bakup$(date '+%Y-%m-%H-%M-%S').sql Enter password: Dump progress: 1/6 tables, 0/3919384 rows Dump progress: 2/6 tables, 635250/3919384 rows Dump progress: 3/6 tables, 1354353/3919384 rows Dump progress: 5/6 tables, 2219935/3919384 rows Dump progress: 5/6 tables, 3066185/3919384 rows Dump completed in 5279 milliseconds [root@localhost mysqlpump2018-06-23-25-49]#
Using mysqlpump to backup selected database and schema:
[root@localhost mysqlpump2018-06-23-25-49]# mysqlpump -u root -p --databases employees.titles > emp.titles$(date '+%Y-%m-%H-%M-%S').sql Enter password: Dump completed in 437 milliseconds [root@localhost mysqlpump2018-06-23-25-49]#
Restore backup from mysqlpump
Both mysqldump and mysqlpump generate MySQL logical backup in .SQL file so restoration is quiet an straightforward process:
mysql -u root -p < backup.SQL
The post How to use mysqlpump for faster MySQL logical backup ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Things to remember when you migrate from MyISAM to InnoDB appeared first on The WebScale Database Infrastructure Operations Experts.
]]>- Data of InnoDB tables is stored in *.ibd files, deleting those files will permanently corrupt your database
- InnoDB tables consumes more storage space than MyISAM tables .
- Unlike MyISAM, InnoDB is a transactional database engine. In any typical MyISAM environment, MySQL DBAs don’t worry much about COMMIT (to finalize the changes) and ROLLBACK (to undo the changes) statements.
- By default, InnoDB tables use setting autocommit=0 and this avoids unnecessary I/O when you are issuing long transactions with consecutive INSERT, UPDATE or DELETE statements, This allows you to issue a ROLLBACK statement to recover lost or garbled data if you make a mistake on the mysql command line or in an exception handler in your application .
- The reliability and scalability features of InnoDB require more disk storage than equivalent MyISAM tables. You might change the column and index definitions slightly, for better space utilization, reduced I/O and memory consumption when processing result sets, and better query optimization plans making efficient use of index lookups.
- InnoDB tables build your data on disk to optimize queries based on primary keys, Each InnoDB table has primary key index called clustered index that organizes the data to minimize disk I/O for primary key lookups.
Convert existing MyISAM to InnoDB table (quick and direct)
ALTER TABLE table_name ENGINE = InnoDB;
Transfer Data from MyISAM to InnoDB table
INSERT INTO innodb_table SELECT * FROM misaim_table ORDER BY primary_key_columns
We recommend indexes creation for InnoDB tables after loading data, loading data on indexed table will seriously impact performance. The same principle applies if you have UNIQUE constraints on secondary keys. Increase size of system variable innodb_buffer_pool_size to 80% of available physical memory for optimal performance.
The post Things to remember when you migrate from MyISAM to InnoDB appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post MariaDB 10.3 support Oracle mode sequences appeared first on The WebScale Database Infrastructure Operations Experts.
]]>Simple steps to create a sequence in MariaDB 10.3 onwards, a create statement is used:
MariaDB [MDB101]> CREATE SEQUENCE Seq1_100
-> START WITH 100
-> INCREMENT BY 1;
Query OK, 0 rows affected (0.015 sec)
This creates a sequence that starts at 100 and is incremented with 1 every time a value is requested from the sequence. The sequence will be visible among the tables in the database, i.e. if you run SHOW TABLES it will be there. You can use DESCRIBE on the sequence to see what columns it has.
To test out the usage of sequences let’s create a table:
MariaDB [MDB101]> CREATE TABLE TAB1 (
-> Col1 int(10) NOT NULL,
-> Col2 varchar(30) NOT NULL,
-> Col3 int(10) NOT NULL,
-> PRIMARY KEY (Col1)
-> );
Query OK, 0 rows affected (0.018 sec)
Since we want to use sequences this time, we did not put AUTO_INCREMENT on the Col1 column. Instead we will ask for the next value from the sequence in the INSERT statements:
MariaDB [MDB101]> INSERT INTO TAB1 (Col1, Col2, Col3) VALUES (NEXT VALUE FOR Seq1_100, 'India', 10); Query OK, 1 row affected (0.011 sec) MariaDB [MDB101]> INSERT INTO TAB1 (Col1, Col2, Col3) VALUES (NEXT VALUE FOR Seq1_100, 'Jakarta', 20); Query OK, 1 row affected (0.008 sec) MariaDB [MDB101]> INSERT INTO TAB1 (Col1, Col2, Col3) VALUES (NEXT VALUE FOR Seq1_100, 'Singapore', 20); Query OK, 1 row affected (0.016 sec) MariaDB [MDB101]> INSERT INTO TAB1 (Col1, Col2, Col3) VALUES (NEXT VALUE FOR Seq1_100, 'Japan', 30); Query OK, 1 row affected (0.007 sec)
Instead of having the NEXT VALUE FOR in each INSERT statement, it could have been the default value of the column in this way:
MariaDB [MDB101]> ALTER TABLE TAB1 MODIFY Col1 int(10) NOT NULL DEFAULT NEXT VALUE FOR Seq1_100; Query OK, 0 rows affected (0.007 sec) Records: 0 Duplicates: 0 Warnings: 0
Running a SELECT over the TAB1 table will look like this:
MariaDB [MDB101]> SELECT * FROM TAB1;; +------+-----------+------+ | Col1 | Col2 | Col3 | +------+-----------+------+ | 100 | India | 10 | | 101 | Jakarta | 20 | | 102 | Singapore | 20 | | 103 | Japan | 30 | +------+-----------+------+ 4 rows in set (0.000 sec)
As we can see the Col1 column has been populated with numbers that start from 100 and are incremented with 1 as defined in the sequence’s CREATE statement. To get the last retrieved number from the sequence PREVIOUS VALUE is used:
MariaDB [MDB101]> SELECT PREVIOUS VALUE FOR Seq1_100; +-----------------------------+ | PREVIOUS VALUE FOR Seq1_100 | +-----------------------------+ | 103 | +-----------------------------+ 1 row in set (0.000 sec)
MariaDB 10.3 shipped another very useful option for sequences is CYCLE, which means that we start again from the beginning after reaching a certain value. For example, if there are 5 phases in a process that are done sequentially and then start again from the beginning, we could easily create a sequence to always be able to retrieve the number of the next phase:
MariaDB [MDB101]> CREATE SEQUENCE Seq1_100_c5
-> START WITH 100
-> INCREMENT BY 1
-> MAXVALUE = 200
-> CYCLE;
Query OK, 0 rows affected (0.012 sec)
The sequence above starts at 100 and is incremented with 1 every time the next value is requested. But when it reaches 200 (MAXVALUE) it will restart from 100 (CYCLE).
We can also set the next value of a sequence, to ALTER a sequence or using sequences in Oracle mode with Oracle specific syntax. To switch to Oracle mode use:
MariaDB [MDB101]> SET SQL_MODE=ORACLE; Query OK, 0 rows affected (0.000 sec)
After that you can retrieve the next value of a sequence in Oracle style:
MariaDB [MDB101]> SELECT Seq1_100.nextval; +------------------+ | Seq1_100.nextval | +------------------+ | 104 | +------------------+ 1 row in set (0.009 sec)
You can read about MariaDB sequences in the documentation, MariaDB documentation
The post MariaDB 10.3 support Oracle mode sequences appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post MySQL 8.0 Data Dictionary appeared first on The WebScale Database Infrastructure Operations Experts.
]]>How file based metadata management used to work in the past (before MySQL 8.0) ?
- Every table in MySQL will have corresponding .frm file, This .frm file stores information like column names and data-types in the binary format, In addition to the .frm file, there are .trn, .trg and .par files to support triggers, trigger namespace and partitioning .
What are major bottlenecks faced due to the usage of file based metadata management ?
- Operationally it always appeared very irrational, Why we need to have an separate mechanism to track the schema information ? Originally this was the idea from Drizzle – Drizzle made it very clear (almost ) that it should get out of the way and let the storage engines be the storage engines and not try to second guess them or keep track of things behind their back.
- Dictionaries out of synch.– Before MySQL 8.0, the data dictionary is a “split brain”, where the “server” and InnoDB have their own separate data dictionary, where some information duplicated. Information that is duplicated in the MySQL server dictionary and the InnoDB dictionary might get out of synch, and we need one common “source of truth” for dictionary information.
- INFORMATION_SCHEMA is the bottleneck– The main reason behind these performance issues in the INFORMATION_SCHEMA (before MySQL 8.0) implementation is that INFORMATION_SCHEMA tables are implemented as temporary tables that are created on-the-fly during query execution. For a MySQL server having hundreds of databases, each with hundreds of tables within them, the INFORMATION_SCHEMA query would end-up doing lot of I/O reading each individual FRM files from the file system. And it would also end-up using more CPU cycles in effort to open the table and prepare related in-memory data structures. It does attempt to use the MySQL server table cache (the system variable ‘table_definition_cache‘), however in large server instances it’s very rare to have a table cache that is large enough to accommodate all of these tables.
- No atomic DDL– Storing the data dictionary in non-transactional tables and files, means that DDLs are unsafe for replication (they are not transactional, not even atomic). If a compound DDL fails we still need to replicate it and hope that it fails with the same error. This is a best effort approach and there is a lot of logic coded to handle this . It is hard to maintain, slows down progress and bloats the replication codebase. The data dictionary is stored partly in non-transactional tables. These are not safe for replication building resilient HA systems on top of MySQL. For instance, some dictionary tables need to be manipulated using regular DML, which causes problems for GTIDs.
- Crash recovery. Since the DDL statements are not atomic, it is challenging to recover after crashing in the middle of a DDL execution, and is especially problematic for replication.
How things are changed with MySQL 8.0 ?
MySQL 8.0 introduced a native data dictionary based on InnoDB. This change has enabled us to get rid of file-based metadata store (FRM files) and also help MySQL to move towards supporting transactional DDL. We have now the metadata of all database tables stored in transactional data dictionary tables, it enables us to design an INFORMATION_SCHEMA table as a database VIEW over the data dictionary tables. This eliminates costs such as the creation of temporary tables for each INFORMATION_SCHEMA query during execution on-the-fly, and also scanning file-system directories to find FRM files. It is also now possible to utilize the full power of the MySQL optimizer to prepare better query execution plans using indexes on data dictionary tables. INFORMATION SCHEMA is now implemented as views over dictionary tables, requires no extra disc accesses, no creation of temporary tables, and is subject to similar handling of character sets and collations as user tables.
The following diagram (Source: MySQL server team blog) explains the difference in design in MySQL 5.7 and 8.0 :
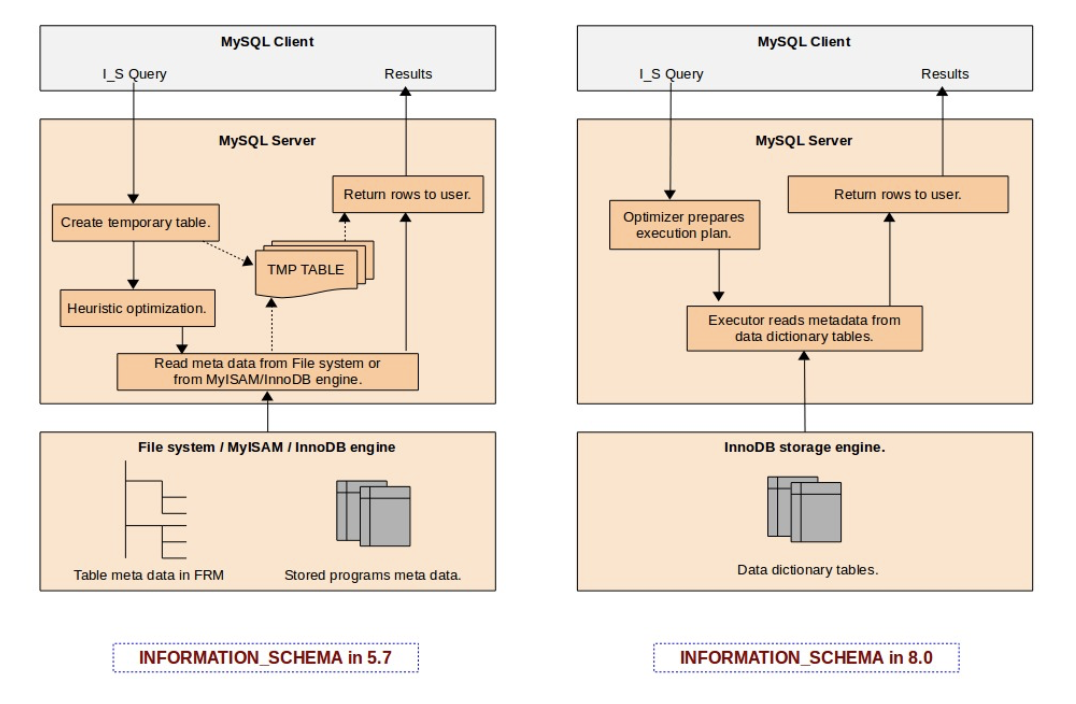
The post MySQL 8.0 Data Dictionary appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post The first impression of MySQL 8 system variable innodb_dedicated_server appeared first on The WebScale Database Infrastructure Operations Experts.
]]>What was our first reaction, when we first read about innodb_dedicated_server ?
Wow, That will be awesome … Indeed, When we manage several hundreds of MySQL instances, This feature will really improve efficiency and DBA Ops. governance.
Now, Let us explain what we have found:
How does innodb_dedicated_server system variable in MySQL 8.0 size the following variables:
- innodb_buffer_pool_size:
- <1G – 128M (default value if innodb_dedicated_server is disabled / OFF)
- <=4G = Detected Physical RAM * 0.5
- >4G : Detected Physical RAM *0.75
- innodb_log_file_size:
- <1G: 48M(default value if innodb_dedicated_server is OFF)
- <=4G: 128M
- <=8G: 512M
- <=16G: 1024M
- >16G: 2G
- innodb_flush_method
- Set to O_DIRECT_NO_FSYNC if the setting is available on the system. If not, set it to the default InnoDB flush method
The first impression of innodb_dedicated_server system variable in MySQL 8.0 is impressive, Definitely will deliver much better performance than default value. This new feature will configure the MySQL system variable mentioned above more intuitively to improve DBA productivity. Till MySQL 5.7 it was always presumed 512M RAM with the default settings.
Are we going to follow this in our daily DBA checklists ?
Not really, We are an very conservative team about implementing the new features immediately in the critical database infrastructure of our customers, Also we are afraid about the isolated issues due to auto sizing of MySQL / InnoDB memory structures, Let’s explain why we will not be using this feature immediately for our MySQL 8.0 customers:
- We carefully size InnoDB memory parameters on various factors like database size, transaction complexity, archiving policies etc. So we want to be hands-on or follow manual sizing of system variables innodb_buffer_pool_size, innodb_log_file_size and innodb_flush_method.
- Capacity planning and sizing – We are always afraid of over / undersizing of our database infrastructure operations. Database infrastructure operations reliability is very critical for us, We have dedicated team with-in to monitor and trend database infrastructure operations and system resource usage consumption.
P.S – innodb_dedicated_server system variable is a relatively new feature, We are confident MySQL engineering team will be improving this component in coming days so our perspective will also change, We will never forget then to blog about this feature and why we are seriously thinking about implementing it for our customer production infrastructure.. Technology keeps changing for good, We are adaptive for the change !
The post The first impression of MySQL 8 system variable innodb_dedicated_server appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post MySQL 8 default character set is utf8mb4 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The UTF-8 is a variable-length encoding. In the case of UTF-8, it means that storing one code point requires one to four bytes. But, In MySQL’s encoding called “utf8” only stores a maximum of three bytes per code point. In the modern web / mobile applications, we have to support for storing not only language characters but also symbols and emojis, Let me show you below some very weird issues faced using MySQL “utf8” :
mysql> SET NAMES utf8; # just to emphasize that the connection charset is set to `utf8` Query OK, 0 rows affected (0.00 sec) mysql> UPDATE custfeeds.reactions SET reacted = 'super like' WHERE id = 13015; Query OK, 1 row affected, 1 warning (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 1 mysql> SELECT reactions FROM custfeeds.reactions WHERE id = 13015; +-------------+ | reactions | +-------------+ | super liked | +-------------+ 1 row in set (0.00 sec) mysql> SHOW WARNINGS; +---------+------+------------------------------------------------------------------------------+ | Level | Code | Message | +---------+------+------------------------------------------------------------------------------+ | Warning | 1366 | Incorrect string value: '\xF0\x9D\x8C\x86' for column 'reactions' at row 731 | +---------+------+------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
MySQL’s utf8 charset can only store UTF-8-encoded symbols that consist of one to three bytes; encoded symbols that take up four bytes aren’t supported. MySQL 5.5.3 released utf8mb4 encoding to solve this problem (https://dev.mysql.com/doc/relnotes/mysql/5.5/en/news-5-5-3.html) so utf8mb4 charset is not a MySQL 8 new feature (yes, It’s now default charset from MySQL8)
MySQL 8 has by default utf8mb4 character set
mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; +--------------------------+--------------------+ | Variable_name | Value | +--------------------------+--------------------+ | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb4 | | character_set_filesystem | binary | | character_set_results | utf8mb4 | | character_set_server | utf8mb4 | | character_set_system | utf8 | | collation_connection | utf8mb4_0900_ai_ci | | collation_database | utf8mb4_0900_ai_ci | | collation_server | utf8mb4_0900_ai_ci | +--------------------------+--------------------+ 10 rows in set (0.01 sec)
How things changed in MySQL 8 with utf8mb4 character set ?
mysql> UPDATE custfeeds.reactions SET reacted = 'super like
mysql> SELECT reactions FROM custfeeds.reactions WHERE id = 13015; +-------------+ | reactions | +-------------+ | super liked
Conclusion
Traditionally MySQL is built for scaling web-scale database infrastructure operations, In the modern web applications / mobile apps. , emojis and a multitude of charsets / collation needs to coexist. To address this compelling need, in MySQL 8.0 default character set has been changed from latin-1 to utf8mb4.
The post MySQL 8 default character set is utf8mb4 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>