The post MinervaDB Database Platforms Virtual Conference 2020 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>Friday, 11 December 2020 (09:00 AM PST to 07:00 PM PST)
MinervaDB is excited to announce an full-stack Open Source Database Systems Conference – MinervaDB Database Platforms Virtual Conference 2020 focussing on MySQL, MariaDB, MyRocks, PostgreSQL, ClickHouse, NoSQL, Columnar Stores, Big Data, SRE and DevOps. addressing performance, scalability and reliability. This is a free virtual conference (hosted on GoToWebinar) and so you don’t have to plan any travels or leave your family / friends during this global pandemic. This conference is scheduled for Friday, 11 December 2020 (09:00 AM PST to 07:00 PM PST) and you can register (100% free) for the conference here. Our call for papers / talks / speakers will be open very soon. If you are interested to be on MinervaDB Database Platforms Virtual Conference 2020 conference committee , Please contact our Founder and Principal Shiv Iyer directly – shiv@minervadb.com and for event sponsorship / advertisements please contact sponsorship@minervadb.com

The post MinervaDB Database Platforms Virtual Conference 2020 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post ClickHouse and ProxySQL queries rewrite (Cross-post from ProxySQL) appeared first on The WebScale Database Infrastructure Operations Experts.
]]>Introduction
ProxySQL in September 2017 announced support for ClickHouse as backend. ProxySQL is a popular open source, high performance and protocol-aware proxy server for MySQL and its forks. ClickHouse is an open source column-oriented database management system capable of real time generation of analytical data reports using SQL queries. To support ClickHouse as a backend, ProxySQL acts as a data bridge between MySQL protocol and ClickHouse protocol, allowing MySQL clients to execute queries in ClickHouse through it. ClickHouse’s SQL query syntax is different than MySQL’s syntax, and migrating application from MySQL to ClickHouse isn’t just a matter of changing connections endpoint but it also requires modifying some queries. This needs development time, but not always possible. One of ProxySQL most widely used feature is indeed the ability of rewriting queries, so often it is just a matter of writing the right query rules. In this blog post we have explained step-by-step MySQL query rewrite for ClickHouse using ProxySQL:
How to implement ProxySQL query rewrite for ClickHouse ?
The below is MySQL query we are considering for query rewrite:
SELECT COUNT(`id`), FROM_UNIXTIME(`created`, '%Y-%m') AS `date` FROM `tablename` GROUP BY FROM_UNIXTIME(`created`, '%Y-%m')
- ClickHouse doesn’t support FROM_UNIXTIME, but it supports toDate and toTime.
- ClickHouse also supports toYear and toMonth , useful to format the date the same FROM_UNIXTIME does.
Therefore, it is possible to rewrite the query as:
SELECT COUNT(`id`), concat(toString(toYear(toDate(created))), '-', toString(toMonth(toDate(created)))) AS `date` FROM `tablename` GROUP BY toYear(toDate(created)), toMonth(toDate(created));
To perform the above rewrite, we will need two rules, one for the first FROM_UNIXTIME, and one for the second one. Or we can just use one rewrite rules to replace FROM_UNIXTIME(created, ‘%Y-%m’) no matter if on the retrieved fields or in the GROUP BY clause, generating the following query:
SELECT COUNT(`id`), concat(toString(toYear(toDate(created))), '-', toString(toMonth(toDate(created)))) AS `date` FROM `tablename` GROUP BY concat(toString(toYear(toDate(created))), '-', toString(toMonth(toDate(created))));
Does it look great? No, not yet!
For the month of March, concat(toString(toYear(toDate(created))), ‘-‘, toString(toMonth(toDate(created)))) will return 2018-3 : not what the application was expecting, as MySQL would return 2018-03 . The same applies for all the first 9 months of each year.
Finally, we rewrote the query as the follow, and the application was happy:
SELECT COUNT(`id`), substring(toString(toDate(created)),1,7) AS `date` FROM `tablename` GROUP BY substring(toString(toDate(created)),1,7);
Note: because of the datatypes conversions that ClickHouse needs to perform in order to execute the above query, its execution time is about 50% slower than executing the following query:
SELECT COUNT(`id`), concat(toString(toYear(toDate(created))), '-', toString(toMonth(toDate(created)))) AS `date` FROM `tablename` GROUP BY toYear(toDate(created)), toMonth(toDate(created));
Architecting using two ProxySQL
Great, we now know how to rewrite the query!
Although, the ClickHouse module in ProxySQL doesn’t support query rewrite. The ClickHouse module in ProxySQL is only responsible to transform data between MySQL and ClickHouse protocol, and viceversa.
Therefore the right way of achieving this solution is to configure two ProxySQL layers, one instance responsible for rewriting the query and sending the rewritten query to the second ProxySQL instance, this one responsible for executing the query (already modified) on ClickHouse.
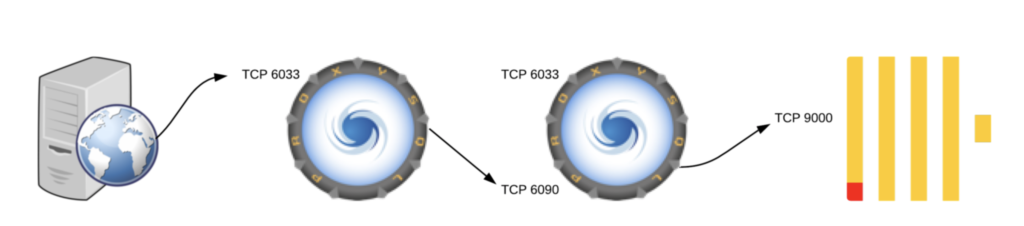
Architecting using only one ProxySQL
Does the above architecture seems complex? Not really, it is reasonable straightforward.
Can it be improved?
As you can see from the previous chart, the ClickHouse module and the MySQL module listen on different ports. The first ProxySQL instance is receiving traffic on port 6033, and sending traffic on the second PorxySQL instance on port 6090.
Are two instances really required? The answer is no.
In fact, a single instance can receive MySQL traffic on port 6033, rewrite the query, and send the rewritten query to itself on port 6090, to finally execute the rewritten query on ClickHouse.
This diagram describes the architecture:
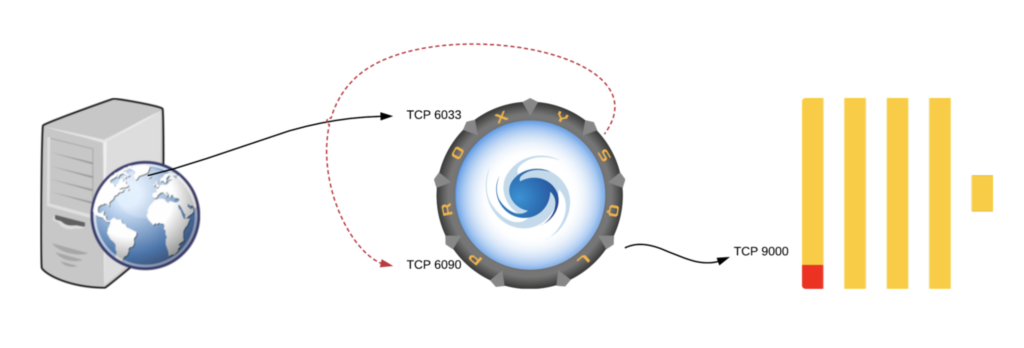
Configuration
For reference, below is the step to configure one single ProxySQL to send traffic to ClickHouse, and use itself as a backend.
Create ClickHouse user:
INSERT INTO clickhouse_users (username,password) VALUES ('clicku','clickp');
LOAD CLICKHOUSE USERS TO RUNTIME;
SAVE CLICKHOUSE USERS TO DISK;
Create MySQL user (same as ClickHouse):
INSERT INTO mysql_users(username,password) SELECT username, password FROM clickhouse_users; LOAD MYSQL USERS TO RUNTIME; SAVE MYSQL USERS TO DISK;
Configure ProxySQL itself as a backend for MySQL traffic:
INSERT INTO mysql_servers(hostname,port) VALUES ('127.0.0.1',6090);
SAVE MYSQL SERVERS TO DISK;
LOAD MYSQL SERVERS TO RUNTIME;
Create a query rule for rewriting queries:
INSERT INTO mysql_query_rules (active,match_pattern,replace_pattern,re_modifiers) VALUES (1,"FROM_UNIXTIME\(`created`, '%Y-%m'\)", 'substring(toString(toDate(created)),1,7)',"CASELESS,GLOBAL"); LOAD MYSQL QUERY RULES TO RUNTIME; SAVE MYSQL QUERY RULES TO DISK;
This is a very simple example to demonstrate how to perform query rewrite from MySQL to ClickHouse using just one ProxySQL instance. In a real world scenarios you will need to create more rules based on your own queries.
Conclusion
Not only ProxySQL allows to send queries to ClickHouse, but it also allows to rewrite queries to solve issues related to different SQL syntax and available functions.
To achieve this, ProxySQL uses its ability to use itself as a backend: rewrite the query in the MySQL module, and execute it in the ClickHouse module.
References
- https://www.proxysql.com/blog/clickhouse-and-proxysql-queries-rewrite
- https://minervadb.com/index.php/2019/12/25/how-to-use-proxysql-to-work-on-clickhouse-like-mysql/
The post ClickHouse and ProxySQL queries rewrite (Cross-post from ProxySQL) appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post How to use ProxySQL to work on ClickHouse like MySQL ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>Introduction
We have several customers on ClickHouse now for both columnar database analytics and archiving MySQL data, You can access data from ClickHouse with clickhouse-client but this involves some learning and also limitations technically. Our customers are very comfortable using MySQL so they always preferred a MySQL client for ClickHouse query analysis and reporting, Thankfully ProxySQL works as a optimal bridge between ClickHouse and MySQL client, This indeed was a great news for us and our customers worldwide. This blog post is about how we can use MySQL client with ClickHouse.
Installation
- https://github.com/sysown/proxysql/releases/ (**Download the package starting with clickhouse )
- Dependencies installation:
- yum -y install perl-DBD-MySQL
Start ProxySQL once completed installation successfully.
# The default configuration file is this: /etc/proxysql.cnf # There is no such data directory by default: mkdir / var / lib / proxysql # start up proxysql --clickhouse-server # ProxySQL will default to daemon mode in the background
Creating ClickHouse user
Create a user for ClickHouse in the ProxySQL with password, The password is not configured for ClickHouse but for accessing ProxySQL:
# ProxySQL port is 6032, the default username and password are written in the configuration file
root@10.xxxx: / root # mysql -h 127.0.0.1 -P 6032 -uadmin -padmin
Welcome to the MariaDB monitor. Commands end with; or \ g.
Your MySQL connection id is 3
Server version: 5.6.81 (ProxySQL Admin Module)
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\ h' for help. Type '\ c' to clear the current input statement.
MySQL [(none)]> INSERT INTO clickhouse_users VALUES ('chuser', 'chpasswd', 1,100);
Query OK, 1 row affected (0.00 sec)
MySQL [(none)] > select * from clickhouse_users;
+ ---------- + ---------- + -------- + ----------------- +
| username | password | active | max_connections |
+ ---------- + ---------- + -------- + ----------------- +
| chuser | chpasswd | 1 | 100 |
+ ---------- + ---------- + -------- + ----------------- +
1 row in set (0.00 sec)
MySQL [(none)]> LOAD CLICKHOUSE USERS TO RUNTIME;
Query OK, 0 rows affected (0.00 sec)
MySQL [(none)]> SAVE CLICKHOUSE USERS TO DISK;
Query OK, 0 rows affected (0.00 sec)
Connecting to ClickHouse from MySQL Client
By default ProxySQL opens the port 6090 to receive user access to ClickHouse:
# Use username and password above # If it is a different machine, remember to change the IP root@10.xxxx: / root # mysql -h 127.0.0.1 -P 6090 -uclicku -pclickp --prompt "ProxySQL-To-ClickHouse>" Welcome to the MariaDB monitor. Commands end with; or \ g. Your MySQL connection id is 64 Server version: 5.6.81 (ProxySQL ClickHouse Module) Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\ h' for help. Type '\ c' to clear the current input statement. ProxySQL-To-ClickHouse >
Querying ClickHouse like MySQL
MySQL [(none)] > select version (); + ------------------- + | version | + ------------------- + | 5.6.81-clickhouse | + ------------------- + 1 row in set (0.00 sec) MySQL [(none)] > select now (); + --------------------- + | now () | + --------------------- + | 2019-12-25 20:17:14 | + --------------------- + 1 row in set (0.00 sec) MySQL [(none)] > select today (); + ------------ + | today () | + ------------ + | 2019-12-25 | + ------------ + 1 row in set (0.00 sec) # Our table is over 55 billion ProxySQL-To-ClickHouse > select count (*) from mysql_audit_log_data; + ------------- + | count () | + ------------- + | 539124837571 | + ------------- + 1 row in set (8.31 sec)
Limitations
- This ProxySQL solution works only when it is on the local ClickHouse (Note.- ClickHouse instance cannot have password in this ecosystem / recommended solution)
- ProxySQL query rewrite limitations – The simple queries work seamless, The complex query rewrite are quite expense and there might some levels of SQL semantics limitations
Conclusion – ProxySQL Version 2.0.8 new features and enhancements
- Changed default max_allowed_packet from 4M to 64M
- Added support for mysqldump 8.0 and Admin #2340
- Added new variable mysql-aurora_max_lag_ms_only_read_from_replicas : if max_lag_ms is used and the writer is in the reader hostgroup, the writer will be excluded if at least N replicas are good candidates.
- Added support for unknown character set , and for collation id greater than 255 #1273
- Added new variable mysql-log_unhealthy_connections to suppress messages related to unhealty clients connections being closed
- Reimplemented rules_fast_routing using khash
- Added support for SET CHARACTERSET #1692
- Added support for same node into multiple Galera clusters #2290
- Added more verbose output for error 2019 (Can’t initialize character set) #2273
- Added more possible values for mysql_replication_hostgroups.check_type #2186
- read_only | innodb_read_only
- read_only & innodb_read_only
- Added support and packages for RHEL / CentOS 8
References:
- http://jackpgao.github.io/2017/12/19/Using-ClickHouse-like-MySQL-by-ProxySQL/
- https://www.proxysql.com/blog/clickhouse-and-proxysql-queries-rewrite
- https://www.altinity.com/blog/2018/7/13/clickhouse-and-proxysql-queries-rewrite
- https://github.com/sysown/proxysql/releases
The post How to use ProxySQL to work on ClickHouse like MySQL ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Building Infrastructure for ClickHouse Performance appeared first on The WebScale Database Infrastructure Operations Experts.
]]>When you are building a very large Database System for analytics on ClickHouse you have to carefully build and operate infrastructure for performance and scalability. Is there any one magic wand to take care of the full-stack performance ? Unfortunately, the answer is no ! If you are not proactively monitoring and sizing the database infrastructure, you may be experiencing severe performance bottleneck or sometimes the total database outage causing serious revenue impact and all these may happen during the peak business hours or season, So where do we start planning for the infrastructure of ClickHouse operations ? As your ClickHouse database grows, the complexity of the queries also increases so we strongly advocate for investing in observability / monitoring infrastructure to troubleshoot more efficiently / proactively, We at MinervaDB use Grafana ( https://grafana.com/grafana/plugins/vertamedia-clickhouse-datasource ) to monitor ClickHouse Operations and record every performance counters from CPU, Network, Memory / RAM and Storage .This blog post is about knowing and monitoring the infrastructure component’s performance to build optimal ClickHouse operations.
Monitor for overheating CPUs
The overheating can damage processor and even motherboard, Closely monitor the systems if you are overclocking and it is exceeding 100C, please turn off the system. Most modern processors do reduce their clockspeed when they get warm to try and cool themselves, This will cause sudden degradation in the performance.
Monitor your current CPU speed:
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq
You can also use turbostat to monitor the CPU load:
sudo ./turbostat --quiet --hide sysfs,IRQ,SMI,CoreTmp,PkgTmp,GFX%rc6,GFXMHz,PkgWatt,CorWatt,GFXWatt Core CPU Avg_MHz Busy% Bzy_MHz TSC_MHz CPU%c1 CPU%c3 CPU%c6 CPU%c7 - - 488 90.71 3900 3498 12.50 0.00 0.00 74.98 0 0 5 0.13 3900 3498 99.87 0.00 0.00 0.00 0 4 3897 99.99 3900 3498 0.01 1 1 0 0.00 3856 3498 0.01 0.00 0.00 99.98 1 5 0 99.00 3861 3498 0.01 2 2 1 0.02 3889 3498 0.03 0.00 0.00 99.95 2 6 0 87.81 3863 3498 0.05 3 3 0 0.01 3869 3498 0.02 0.00 0.00 99.97 3 7 0 0.00 3878 3498 0.03 Core CPU Avg_MHz Busy% Bzy_MHz TSC_MHz CPU%c1 CPU%c3 CPU%c6 CPU%c7 - - 491 82.79 3900 3498 12.42 0.00 0.00 74.99 0 0 27 0.69 3900 3498 99.31 0.00 0.00 0.00 0 4 3898 99.99 3900 3498 0.01 1 1 0 0.00 3883 3498 0.01 0.00 0.00 99.99 1 5 0 0.00 3898 3498 56.61 2 2 0 0.01 3889 3498 0.02 0.00 0.00 99.98 2 6 0 0.00 3889 3498 0.02 3 3 0 0.00 3856 3498 0.01 0.00 0.00 99.99 3 7 0 0.00 3897 3498 0.01
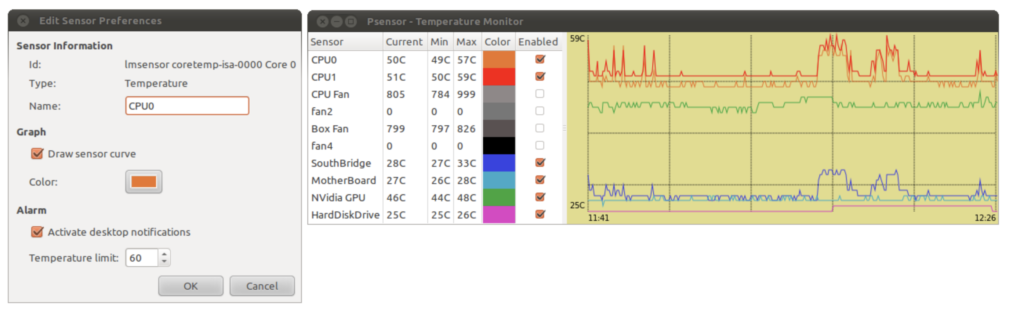
Using PSENSOR to monitor hardware temperature
psensor is a graphical hardware temperature monitor for Linux.
It can monitor:
- the temperature of the motherboard and CPU sensors (using lm-sensors).
- the temperature of the NVidia GPUs (using XNVCtrl).
- the temperature of ATI/AMD GPUs (not enabled in official distribution repositories, see the instructions for enabling its support).
- the temperature of the Hard Disk Drives (using hddtemp or libatasmart).
- the rotation speed of the fans (using lm-sensors).
- the CPU usage (since 0.6.2.10 and using Gtop2).
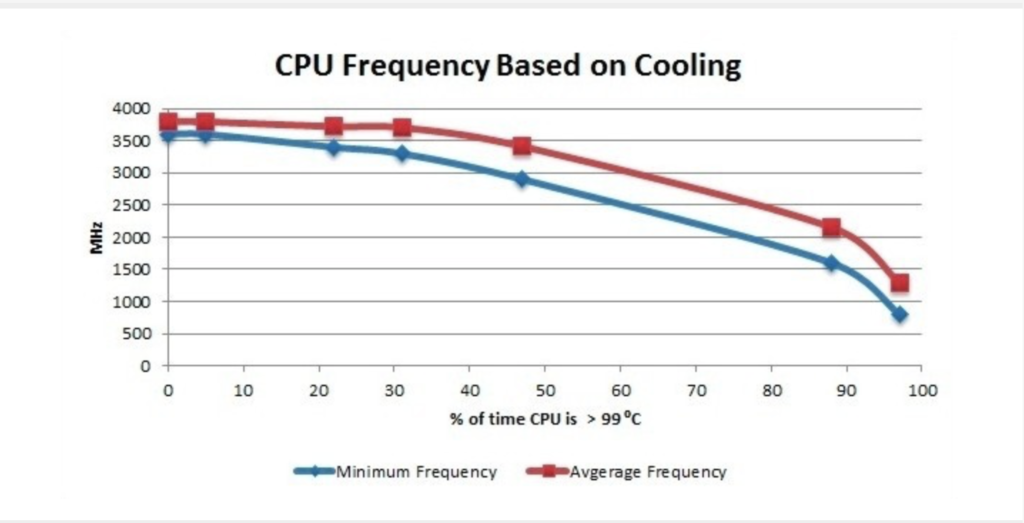
Since the Intel CPU thermal limit is 100 °C, we can quantify the amount of overheating by measuring the amount of time the CPU temperature was running at > 99 °C
Choosing RAID for Performance
The table below explains different RAID levels and how they impact on performance:
| RAID Level | Advantages | Disadvantages |
|---|---|---|
| RAID level 0 – Striping | RAID 0 offers great performance, both in read and write operations. There is no overhead caused by parity controls.RAID 0 offers great performance, both in read and write operations. All storage capacity is used, there is no overhead. | RAID 0 is not fault-tolerant. If one drive fails, all data in the RAID 0 array are lost. It should not be used for mission-critical systems. |
| RAID level 1 – Mirroring | RAID 1 offers excellent read speed and a write-speed that is comparable to that of a single drive. In case a drive fails, data do not have to be rebuild, they just have to be copied to the replacement drive. | Software RAID 1 solutions do not always allow a hot swap of a failed drive. That means the failed drive can only be replaced after powering down the computer it is attached to. For servers that are used simultaneously by many people, this may not be acceptable. Such systems typically use hardware controllers that do support hot swapping. The main disadvantage is that the effective storage capacity is only half of the total drive capacity because all data get written twice. |
| RAID level 5 | Read data transactions are very fast while write data transactions are somewhat slower (due to the parity that has to be calculated). If a drive fails, you still have access to all data, even while the failed drive is being replaced and the storage controller rebuilds the data on the new drive. | Technology complexity - If one of the disks in an array using 4TB disks fails and is replaced, restoring the data (the rebuild time) may take a day or longer, depending on the load on the array and the speed of the controller. If another disk goes bad during that time, data are lost forever. |
| RAID level 6 – Striping with double parity | READs are very fast, If two drives fail, you still have access to all data, even while the failed drives are being replaced. So RAID 6 is more secure than RAID 5. | Technology complexity - Rebuilding an array in which one drive failed can take a long time. Write data transactions are slower than RAID 5 due to the additional parity data that have to be calculated. In one report I read the write performance was 20% lower. |
| RAID level 10 – combining RAID 1 & RAID 0 | High Performance and Fault Tolerant - If something goes wrong, All we need to do is copying all the data from the surviving mirror to a new drive. | Highly expensive - Half of the storage capacity goes directly for mirroring. |
- Use NCQ with a long queue.
- Use CFQ scheduler for HDD.
- Enable write cache for improved WRITEs performance.
- Use noop for SSD.
- Ext4 is the most reliable.
You can read a detailed blog post about RAID here – https://minervadb.com/index.php/2019/08/04/raid-redundant-storage-for-database-reliability/
Huge Pages
What are Transparent Huge Pages and why they exist ? Operating Systems, Database Systems and several applications run in virtual memory. The Operating System manage virtual memory using pages (contiguous block of memory). Technically virtual memory is mapped to physical memory by the Operating System maintaining the page tables data structure in RAM. The address translation logic (page table walking) is implemented by the CPU’s memory management unit (MMU). The MMU also has a cache of recently used pages. This cache is called the Translation lookaside buffer (TLB).
Operating Systems manage virtual memory using pages (contiguous block of memory). Typically, the size of a memory page is 4 KB. 1 GB of memory is 256 000 pages; 128 GB is 32 768 000 pages. Obviously TLB cache can’t fit all of the pages and performance suffers from cache misses. There are two main ways to improve it. The first one is to increase TLB size, which is expensive and won’t help significantly. Another one is to increase the page size and therefore have less pages to map. Modern OSes and CPUs support large 2 MB and even 1 GB pages. Using large 2 MB pages, 128 GB of memory becomes just 64 000 pages.
Transparent Hugepage Support in Linux exist for performance. Transparent Huge Pages manages large pages automatically and transparently for applications. The benefits are pretty obvious: no changes required on application side; it reduces the number of TLB misses; page table walking becomes cheaper. The feature logically can be divided into two parts: allocation and maintenance. The THP takes the regular (“higher-order”) memory allocation path and it requires that the OS be able to find contiguous and aligned block of memory. It suffers from the same issues as the regular pages, namely fragmentation. If the OS can’t find a contiguous block of memory, it will try to compact, reclaim or page out other pages. That process is expensive and could cause latency spikes (up to seconds). This issue was addressed in the 4.6 kernel (via “defer” option), the OS falls back to a regular page if it can’t allocate a large one. The second part is maintenance. Even if an application touches just 1 byte of memory, it will consume whole 2 MB large page. This is obviously a waste of memory. So there’s a background kernel thread called “khugepaged”. It scans pages and tries to defragment and collapse them into one huge page. Despite it’s a background thread, it locks pages it works with, hence could cause latency spikes too. Another pitfall lays in large page splitting, not all parts of the OS work with large pages, e.g. swap. The OS splits large pages into regular ones for them. It could also degrade the performance and increase memory fragmentation.
Why we recommend to disable Transparent Huge Pages for ClickHouse Performance ?
Transparent Huge Pages (THP) is a Linux memory management system that reduces the overhead of Translation Lookaside Buffer (TLB) lookups on machines with large amounts of memory by using larger memory pages.
However, In our experience ClickHouse often perform poorly with THP enabled, because they tend to have sparse rather than contiguous memory access patterns. When running ClickHouse on Linux, THP should be disabled for best performance.
$ echo 'never' | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
Yandex recommends perf top to monitor the time spend in the kernel for memory management.
RAM
ClickHouse performs great with the high quality investments on RAM. As the data volumes increases, caching benefits more to the frequently executed SORT / SEARCH intensive analytical queries . “Yandex recommends you not to disable overcommit”. The value cat /proc/sys/vm/overcommit_memory should be 0 or 1. Run
$ echo 0 | sudo tee /proc/sys/vm/overcommit_memory
Conclusion
The visibility to ClickHouse Ops. is very important to build optimal, scalable and highly available Data Analytics platforms, Most often what happens is we measure the hardware infrastructure when there is a performance bottleneck and the reactive approach to troubleshoot performance is really expensive. When we work with our customers, we plan and conduct regular performance audits of their ClickHouse Ops. for right sizing their infrastructure.
References:
- https://alexandrnikitin.github.io/
- https://blogs.intel.com
- https://www.kernel.org/doc/Documentation/vm/transhuge.txt
- https://clickhouse.yandex/docs/en/
The post Building Infrastructure for ClickHouse Performance appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Benchmarking ClickHouse Performance on Amazon EC2 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>Amazon EC2 infrastructure used for benchmarking ClickHouse:
- Amazon EC2 instance details – R5DN Eight Extra Large / r5dn.8xlarge
- RAM – 256.0 GiB
- vCPUs – 32
- Storage – 1200 GiB (2 * 600 GiB NVMe SSD)
- Network performance – 25 Gigabit
Benchmarking Dataset – New York Taxi data
Data source :
https://github.com/toddwschneider/nyc-taxi-data
http://tech.marksblogg.com/billion-nyc-taxi-rides-redshift.html
You can either import raw data (from above sources  ) or download prepared partitions
) or download prepared partitions
Downloading the prepared partitions
$ curl -O https://clickhouse-datasets.s3.yandex.net/trips_mergetree/partitions/trips_mergetree.tar $ tar xvf trips_mergetree.tar -C /var/lib/clickhouse # path to ClickHouse data directory $ # check permissions of unpacked data, fix if required $ sudo service clickhouse-server restart $ clickhouse-client --query "select count(*) from datasets.trips_mergetree"
The entire download will be an uncompressed CSV data files of 227 GB in size, It takes approximately 50 minutes with 1Gbit of connection. The data must be pre-processed in PostgreSQL before loading to ClickHouse
$ time psql nyc-taxi-data -c "SELECT count(*) FROM trips;" ## Count 1299989791 (1 row) real 4m1.274s
Approx. 1.3 Billion records in PostgreSQL with database size of around 390 GB.
Exporting data from PostgreSQL:
COPY ( SELECT trips.id, trips.vendor_id, trips.pickup_datetime, trips.dropoff_datetime, trips.store_and_fwd_flag, trips.rate_code_id, trips.pickup_longitude, trips.pickup_latitude, trips.dropoff_longitude, trips.dropoff_latitude, trips.passenger_count, trips.trip_distance, trips.fare_amount, trips.extra, trips.mta_tax, trips.tip_amount, trips.tolls_amount, trips.ehail_fee, trips.improvement_surcharge, trips.total_amount, trips.payment_type, trips.trip_type, trips.pickup, trips.dropoff, cab_types.type cab_type, weather.precipitation_tenths_of_mm rain, weather.snow_depth_mm, weather.snowfall_mm, weather.max_temperature_tenths_degrees_celsius max_temp, weather.min_temperature_tenths_degrees_celsius min_temp, weather.average_wind_speed_tenths_of_meters_per_second wind, pick_up.gid pickup_nyct2010_gid, pick_up.ctlabel pickup_ctlabel, pick_up.borocode pickup_borocode, pick_up.boroname pickup_boroname, pick_up.ct2010 pickup_ct2010, pick_up.boroct2010 pickup_boroct2010, pick_up.cdeligibil pickup_cdeligibil, pick_up.ntacode pickup_ntacode, pick_up.ntaname pickup_ntaname, pick_up.puma pickup_puma, drop_off.gid dropoff_nyct2010_gid, drop_off.ctlabel dropoff_ctlabel, drop_off.borocode dropoff_borocode, drop_off.boroname dropoff_boroname, drop_off.ct2010 dropoff_ct2010, drop_off.boroct2010 dropoff_boroct2010, drop_off.cdeligibil dropoff_cdeligibil, drop_off.ntacode dropoff_ntacode, drop_off.ntaname dropoff_ntaname, drop_off.puma dropoff_puma FROM trips LEFT JOIN cab_types ON trips.cab_type_id = cab_types.id LEFT JOIN central_park_weather_observations_raw weather ON weather.date = trips.pickup_datetime::date LEFT JOIN nyct2010 pick_up ON pick_up.gid = trips.pickup_nyct2010_gid LEFT JOIN nyct2010 drop_off ON drop_off.gid = trips.dropoff_nyct2010_gid ) TO '/opt/milovidov/nyc-taxi-data/trips.tsv';
The entire activity will be completed in approx. 4 hours , the data snapshot speed was around 80MB per second and TSV file size is 590612904969 bytes.
For data cleansing and removing NULLs we will create a temporary table in ClickHouse:
CREATE TABLE trips ( trip_id UInt32, vendor_id String, pickup_datetime DateTime, dropoff_datetime Nullable(DateTime), store_and_fwd_flag Nullable(FixedString(1)), rate_code_id Nullable(UInt8), pickup_longitude Nullable(Float64), pickup_latitude Nullable(Float64), dropoff_longitude Nullable(Float64), dropoff_latitude Nullable(Float64), passenger_count Nullable(UInt8), trip_distance Nullable(Float64), fare_amount Nullable(Float32), extra Nullable(Float32), mta_tax Nullable(Float32), tip_amount Nullable(Float32), tolls_amount Nullable(Float32), ehail_fee Nullable(Float32), improvement_surcharge Nullable(Float32), total_amount Nullable(Float32), payment_type Nullable(String), trip_type Nullable(UInt8), pickup Nullable(String), dropoff Nullable(String), cab_type Nullable(String), precipitation Nullable(UInt8), snow_depth Nullable(UInt8), snowfall Nullable(UInt8), max_temperature Nullable(UInt8), min_temperature Nullable(UInt8), average_wind_speed Nullable(UInt8), pickup_nyct2010_gid Nullable(UInt8), pickup_ctlabel Nullable(String), pickup_borocode Nullable(UInt8), pickup_boroname Nullable(String), pickup_ct2010 Nullable(String), pickup_boroct2010 Nullable(String), pickup_cdeligibil Nullable(FixedString(1)), pickup_ntacode Nullable(String), pickup_ntaname Nullable(String), pickup_puma Nullable(String), dropoff_nyct2010_gid Nullable(UInt8), dropoff_ctlabel Nullable(String), dropoff_borocode Nullable(UInt8), dropoff_boroname Nullable(String), dropoff_ct2010 Nullable(String), dropoff_boroct2010 Nullable(String), dropoff_cdeligibil Nullable(String), dropoff_ntacode Nullable(String), dropoff_ntaname Nullable(String), dropoff_puma Nullable(String) ) ENGINE = Log;
$ time clickhouse-client --query="INSERT INTO trips FORMAT TabSeparated" < trips.tsv real 61m38.597s
I have done this benchmarking on a single ClickHouse server using MergeTree engine , Created Summary Table & loaded data below:
CREATE TABLE trips_mergetree
ENGINE = MergeTree(pickup_date, pickup_datetime, 8192)
AS SELECT
trip_id,
CAST(vendor_id AS Enum8('1' = 1, '2' = 2, 'CMT' = 3, 'VTS' = 4, 'DDS' = 5, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14)) AS vendor_id,
toDate(pickup_datetime) AS pickup_date,
ifNull(pickup_datetime, toDateTime(0)) AS pickup_datetime,
toDate(dropoff_datetime) AS dropoff_date,
ifNull(dropoff_datetime, toDateTime(0)) AS dropoff_datetime,
assumeNotNull(store_and_fwd_flag) IN ('Y', '1', '2') AS store_and_fwd_flag,
assumeNotNull(rate_code_id) AS rate_code_id,
assumeNotNull(pickup_longitude) AS pickup_longitude,
assumeNotNull(pickup_latitude) AS pickup_latitude,
assumeNotNull(dropoff_longitude) AS dropoff_longitude,
assumeNotNull(dropoff_latitude) AS dropoff_latitude,
assumeNotNull(passenger_count) AS passenger_count,
assumeNotNull(trip_distance) AS trip_distance,
assumeNotNull(fare_amount) AS fare_amount,
assumeNotNull(extra) AS extra,
assumeNotNull(mta_tax) AS mta_tax,
assumeNotNull(tip_amount) AS tip_amount,
assumeNotNull(tolls_amount) AS tolls_amount,
assumeNotNull(ehail_fee) AS ehail_fee,
assumeNotNull(improvement_surcharge) AS improvement_surcharge,
assumeNotNull(total_amount) AS total_amount,
CAST((assumeNotNull(payment_type) AS pt) IN ('CSH', 'CASH', 'Cash', 'CAS', 'Cas', '1') ? 'CSH' : (pt IN ('CRD', 'Credit', 'Cre', 'CRE', 'CREDIT', '2') ? 'CRE' : (pt IN ('NOC', 'No Charge', 'No', '3') ? 'NOC' : (pt IN ('DIS', 'Dispute', 'Dis', '4') ? 'DIS' : 'UNK'))) AS Enum8('CSH' = 1, 'CRE' = 2, 'UNK' = 0, 'NOC' = 3, 'DIS' = 4)) AS payment_type_,
assumeNotNull(trip_type) AS trip_type,
ifNull(toFixedString(unhex(pickup), 25), toFixedString('', 25)) AS pickup,
ifNull(toFixedString(unhex(dropoff), 25), toFixedString('', 25)) AS dropoff,
CAST(assumeNotNull(cab_type) AS Enum8('yellow' = 1, 'green' = 2, 'uber' = 3)) AS cab_type,
assumeNotNull(pickup_nyct2010_gid) AS pickup_nyct2010_gid,
toFloat32(ifNull(pickup_ctlabel, '0')) AS pickup_ctlabel,
assumeNotNull(pickup_borocode) AS pickup_borocode,
CAST(assumeNotNull(pickup_boroname) AS Enum8('Manhattan' = 1, 'Queens' = 4, 'Brooklyn' = 3, '' = 0, 'Bronx' = 2, 'Staten Island' = 5)) AS pickup_boroname,
toFixedString(ifNull(pickup_ct2010, '000000'), 6) AS pickup_ct2010,
toFixedString(ifNull(pickup_boroct2010, '0000000'), 7) AS pickup_boroct2010,
CAST(assumeNotNull(ifNull(pickup_cdeligibil, ' ')) AS Enum8(' ' = 0, 'E' = 1, 'I' = 2)) AS pickup_cdeligibil,
toFixedString(ifNull(pickup_ntacode, '0000'), 4) AS pickup_ntacode,
CAST(assumeNotNull(pickup_ntaname) AS Enum16('' = 0, 'Airport' = 1, 'Allerton-Pelham Gardens' = 2, 'Annadale-Huguenot-Prince\'s Bay-Eltingville' = 3, 'Arden Heights' = 4, 'Astoria' = 5, 'Auburndale' = 6, 'Baisley Park' = 7, 'Bath Beach' = 8, 'Battery Park City-Lower Manhattan' = 9, 'Bay Ridge' = 10, 'Bayside-Bayside Hills' = 11, 'Bedford' = 12, 'Bedford Park-Fordham North' = 13, 'Bellerose' = 14, 'Belmont' = 15, 'Bensonhurst East' = 16, 'Bensonhurst West' = 17, 'Borough Park' = 18, 'Breezy Point-Belle Harbor-Rockaway Park-Broad Channel' = 19, 'Briarwood-Jamaica Hills' = 20, 'Brighton Beach' = 21, 'Bronxdale' = 22, 'Brooklyn Heights-Cobble Hill' = 23, 'Brownsville' = 24, 'Bushwick North' = 25, 'Bushwick South' = 26, 'Cambria Heights' = 27, 'Canarsie' = 28, 'Carroll Gardens-Columbia Street-Red Hook' = 29, 'Central Harlem North-Polo Grounds' = 30, 'Central Harlem South' = 31, 'Charleston-Richmond Valley-Tottenville' = 32, 'Chinatown' = 33, 'Claremont-Bathgate' = 34, 'Clinton' = 35, 'Clinton Hill' = 36, 'Co-op City' = 37, 'College Point' = 38, 'Corona' = 39, 'Crotona Park East' = 40, 'Crown Heights North' = 41, 'Crown Heights South' = 42, 'Cypress Hills-City Line' = 43, 'DUMBO-Vinegar Hill-Downtown Brooklyn-Boerum Hill' = 44, 'Douglas Manor-Douglaston-Little Neck' = 45, 'Dyker Heights' = 46, 'East Concourse-Concourse Village' = 47, 'East Elmhurst' = 48, 'East Flatbush-Farragut' = 49, 'East Flushing' = 50, 'East Harlem North' = 51, 'East Harlem South' = 52, 'East New York' = 53, 'East New York (Pennsylvania Ave)' = 54, 'East Tremont' = 55, 'East Village' = 56, 'East Williamsburg' = 57, 'Eastchester-Edenwald-Baychester' = 58, 'Elmhurst' = 59, 'Elmhurst-Maspeth' = 60, 'Erasmus' = 61, 'Far Rockaway-Bayswater' = 62, 'Flatbush' = 63, 'Flatlands' = 64, 'Flushing' = 65, 'Fordham South' = 66, 'Forest Hills' = 67, 'Fort Greene' = 68, 'Fresh Meadows-Utopia' = 69, 'Ft. Totten-Bay Terrace-Clearview' = 70, 'Georgetown-Marine Park-Bergen Beach-Mill Basin' = 71, 'Glen Oaks-Floral Park-New Hyde Park' = 72, 'Glendale' = 73, 'Gramercy' = 74, 'Grasmere-Arrochar-Ft. Wadsworth' = 75, 'Gravesend' = 76, 'Great Kills' = 77, 'Greenpoint' = 78, 'Grymes Hill-Clifton-Fox Hills' = 79, 'Hamilton Heights' = 80, 'Hammels-Arverne-Edgemere' = 81, 'Highbridge' = 82, 'Hollis' = 83, 'Homecrest' = 84, 'Hudson Yards-Chelsea-Flatiron-Union Square' = 85, 'Hunters Point-Sunnyside-West Maspeth' = 86, 'Hunts Point' = 87, 'Jackson Heights' = 88, 'Jamaica' = 89, 'Jamaica Estates-Holliswood' = 90, 'Kensington-Ocean Parkway' = 91, 'Kew Gardens' = 92, 'Kew Gardens Hills' = 93, 'Kingsbridge Heights' = 94, 'Laurelton' = 95, 'Lenox Hill-Roosevelt Island' = 96, 'Lincoln Square' = 97, 'Lindenwood-Howard Beach' = 98, 'Longwood' = 99, 'Lower East Side' = 100, 'Madison' = 101, 'Manhattanville' = 102, 'Marble Hill-Inwood' = 103, 'Mariner\'s Harbor-Arlington-Port Ivory-Graniteville' = 104, 'Maspeth' = 105, 'Melrose South-Mott Haven North' = 106, 'Middle Village' = 107, 'Midtown-Midtown South' = 108, 'Midwood' = 109, 'Morningside Heights' = 110, 'Morrisania-Melrose' = 111, 'Mott Haven-Port Morris' = 112, 'Mount Hope' = 113, 'Murray Hill' = 114, 'Murray Hill-Kips Bay' = 115, 'New Brighton-Silver Lake' = 116, 'New Dorp-Midland Beach' = 117, 'New Springville-Bloomfield-Travis' = 118, 'North Corona' = 119, 'North Riverdale-Fieldston-Riverdale' = 120, 'North Side-South Side' = 121, 'Norwood' = 122, 'Oakland Gardens' = 123, 'Oakwood-Oakwood Beach' = 124, 'Ocean Hill' = 125, 'Ocean Parkway South' = 126, 'Old Astoria' = 127, 'Old Town-Dongan Hills-South Beach' = 128, 'Ozone Park' = 129, 'Park Slope-Gowanus' = 130, 'Parkchester' = 131, 'Pelham Bay-Country Club-City Island' = 132, 'Pelham Parkway' = 133, 'Pomonok-Flushing Heights-Hillcrest' = 134, 'Port Richmond' = 135, 'Prospect Heights' = 136, 'Prospect Lefferts Gardens-Wingate' = 137, 'Queens Village' = 138, 'Queensboro Hill' = 139, 'Queensbridge-Ravenswood-Long Island City' = 140, 'Rego Park' = 141, 'Richmond Hill' = 142, 'Ridgewood' = 143, 'Rikers Island' = 144, 'Rosedale' = 145, 'Rossville-Woodrow' = 146, 'Rugby-Remsen Village' = 147, 'Schuylerville-Throgs Neck-Edgewater Park' = 148, 'Seagate-Coney Island' = 149, 'Sheepshead Bay-Gerritsen Beach-Manhattan Beach' = 150, 'SoHo-TriBeCa-Civic Center-Little Italy' = 151, 'Soundview-Bruckner' = 152, 'Soundview-Castle Hill-Clason Point-Harding Park' = 153, 'South Jamaica' = 154, 'South Ozone Park' = 155, 'Springfield Gardens North' = 156, 'Springfield Gardens South-Brookville' = 157, 'Spuyten Duyvil-Kingsbridge' = 158, 'St. Albans' = 159, 'Stapleton-Rosebank' = 160, 'Starrett City' = 161, 'Steinway' = 162, 'Stuyvesant Heights' = 163, 'Stuyvesant Town-Cooper Village' = 164, 'Sunset Park East' = 165, 'Sunset Park West' = 166, 'Todt Hill-Emerson Hill-Heartland Village-Lighthouse Hill' = 167, 'Turtle Bay-East Midtown' = 168, 'University Heights-Morris Heights' = 169, 'Upper East Side-Carnegie Hill' = 170, 'Upper West Side' = 171, 'Van Cortlandt Village' = 172, 'Van Nest-Morris Park-Westchester Square' = 173, 'Washington Heights North' = 174, 'Washington Heights South' = 175, 'West Brighton' = 176, 'West Concourse' = 177, 'West Farms-Bronx River' = 178, 'West New Brighton-New Brighton-St. George' = 179, 'West Village' = 180, 'Westchester-Unionport' = 181, 'Westerleigh' = 182, 'Whitestone' = 183, 'Williamsbridge-Olinville' = 184, 'Williamsburg' = 185, 'Windsor Terrace' = 186, 'Woodhaven' = 187, 'Woodlawn-Wakefield' = 188, 'Woodside' = 189, 'Yorkville' = 190, 'park-cemetery-etc-Bronx' = 191, 'park-cemetery-etc-Brooklyn' = 192, 'park-cemetery-etc-Manhattan' = 193, 'park-cemetery-etc-Queens' = 194, 'park-cemetery-etc-Staten Island' = 195)) AS pickup_ntaname,
toUInt16(ifNull(pickup_puma, '0')) AS pickup_puma,
assumeNotNull(dropoff_nyct2010_gid) AS dropoff_nyct2010_gid,
toFloat32(ifNull(dropoff_ctlabel, '0')) AS dropoff_ctlabel,
assumeNotNull(dropoff_borocode) AS dropoff_borocode,
CAST(assumeNotNull(dropoff_boroname) AS Enum8('Manhattan' = 1, 'Queens' = 4, 'Brooklyn' = 3, '' = 0, 'Bronx' = 2, 'Staten Island' = 5)) AS dropoff_boroname,
toFixedString(ifNull(dropoff_ct2010, '000000'), 6) AS dropoff_ct2010,
toFixedString(ifNull(dropoff_boroct2010, '0000000'), 7) AS dropoff_boroct2010,
CAST(assumeNotNull(ifNull(dropoff_cdeligibil, ' ')) AS Enum8(' ' = 0, 'E' = 1, 'I' = 2)) AS dropoff_cdeligibil,
toFixedString(ifNull(dropoff_ntacode, '0000'), 4) AS dropoff_ntacode,
CAST(assumeNotNull(dropoff_ntaname) AS Enum16('' = 0, 'Airport' = 1, 'Allerton-Pelham Gardens' = 2, 'Annadale-Huguenot-Prince\'s Bay-Eltingville' = 3, 'Arden Heights' = 4, 'Astoria' = 5, 'Auburndale' = 6, 'Baisley Park' = 7, 'Bath Beach' = 8, 'Battery Park City-Lower Manhattan' = 9, 'Bay Ridge' = 10, 'Bayside-Bayside Hills' = 11, 'Bedford' = 12, 'Bedford Park-Fordham North' = 13, 'Bellerose' = 14, 'Belmont' = 15, 'Bensonhurst East' = 16, 'Bensonhurst West' = 17, 'Borough Park' = 18, 'Breezy Point-Belle Harbor-Rockaway Park-Broad Channel' = 19, 'Briarwood-Jamaica Hills' = 20, 'Brighton Beach' = 21, 'Bronxdale' = 22, 'Brooklyn Heights-Cobble Hill' = 23, 'Brownsville' = 24, 'Bushwick North' = 25, 'Bushwick South' = 26, 'Cambria Heights' = 27, 'Canarsie' = 28, 'Carroll Gardens-Columbia Street-Red Hook' = 29, 'Central Harlem North-Polo Grounds' = 30, 'Central Harlem South' = 31, 'Charleston-Richmond Valley-Tottenville' = 32, 'Chinatown' = 33, 'Claremont-Bathgate' = 34, 'Clinton' = 35, 'Clinton Hill' = 36, 'Co-op City' = 37, 'College Point' = 38, 'Corona' = 39, 'Crotona Park East' = 40, 'Crown Heights North' = 41, 'Crown Heights South' = 42, 'Cypress Hills-City Line' = 43, 'DUMBO-Vinegar Hill-Downtown Brooklyn-Boerum Hill' = 44, 'Douglas Manor-Douglaston-Little Neck' = 45, 'Dyker Heights' = 46, 'East Concourse-Concourse Village' = 47, 'East Elmhurst' = 48, 'East Flatbush-Farragut' = 49, 'East Flushing' = 50, 'East Harlem North' = 51, 'East Harlem South' = 52, 'East New York' = 53, 'East New York (Pennsylvania Ave)' = 54, 'East Tremont' = 55, 'East Village' = 56, 'East Williamsburg' = 57, 'Eastchester-Edenwald-Baychester' = 58, 'Elmhurst' = 59, 'Elmhurst-Maspeth' = 60, 'Erasmus' = 61, 'Far Rockaway-Bayswater' = 62, 'Flatbush' = 63, 'Flatlands' = 64, 'Flushing' = 65, 'Fordham South' = 66, 'Forest Hills' = 67, 'Fort Greene' = 68, 'Fresh Meadows-Utopia' = 69, 'Ft. Totten-Bay Terrace-Clearview' = 70, 'Georgetown-Marine Park-Bergen Beach-Mill Basin' = 71, 'Glen Oaks-Floral Park-New Hyde Park' = 72, 'Glendale' = 73, 'Gramercy' = 74, 'Grasmere-Arrochar-Ft. Wadsworth' = 75, 'Gravesend' = 76, 'Great Kills' = 77, 'Greenpoint' = 78, 'Grymes Hill-Clifton-Fox Hills' = 79, 'Hamilton Heights' = 80, 'Hammels-Arverne-Edgemere' = 81, 'Highbridge' = 82, 'Hollis' = 83, 'Homecrest' = 84, 'Hudson Yards-Chelsea-Flatiron-Union Square' = 85, 'Hunters Point-Sunnyside-West Maspeth' = 86, 'Hunts Point' = 87, 'Jackson Heights' = 88, 'Jamaica' = 89, 'Jamaica Estates-Holliswood' = 90, 'Kensington-Ocean Parkway' = 91, 'Kew Gardens' = 92, 'Kew Gardens Hills' = 93, 'Kingsbridge Heights' = 94, 'Laurelton' = 95, 'Lenox Hill-Roosevelt Island' = 96, 'Lincoln Square' = 97, 'Lindenwood-Howard Beach' = 98, 'Longwood' = 99, 'Lower East Side' = 100, 'Madison' = 101, 'Manhattanville' = 102, 'Marble Hill-Inwood' = 103, 'Mariner\'s Harbor-Arlington-Port Ivory-Graniteville' = 104, 'Maspeth' = 105, 'Melrose South-Mott Haven North' = 106, 'Middle Village' = 107, 'Midtown-Midtown South' = 108, 'Midwood' = 109, 'Morningside Heights' = 110, 'Morrisania-Melrose' = 111, 'Mott Haven-Port Morris' = 112, 'Mount Hope' = 113, 'Murray Hill' = 114, 'Murray Hill-Kips Bay' = 115, 'New Brighton-Silver Lake' = 116, 'New Dorp-Midland Beach' = 117, 'New Springville-Bloomfield-Travis' = 118, 'North Corona' = 119, 'North Riverdale-Fieldston-Riverdale' = 120, 'North Side-South Side' = 121, 'Norwood' = 122, 'Oakland Gardens' = 123, 'Oakwood-Oakwood Beach' = 124, 'Ocean Hill' = 125, 'Ocean Parkway South' = 126, 'Old Astoria' = 127, 'Old Town-Dongan Hills-South Beach' = 128, 'Ozone Park' = 129, 'Park Slope-Gowanus' = 130, 'Parkchester' = 131, 'Pelham Bay-Country Club-City Island' = 132, 'Pelham Parkway' = 133, 'Pomonok-Flushing Heights-Hillcrest' = 134, 'Port Richmond' = 135, 'Prospect Heights' = 136, 'Prospect Lefferts Gardens-Wingate' = 137, 'Queens Village' = 138, 'Queensboro Hill' = 139, 'Queensbridge-Ravenswood-Long Island City' = 140, 'Rego Park' = 141, 'Richmond Hill' = 142, 'Ridgewood' = 143, 'Rikers Island' = 144, 'Rosedale' = 145, 'Rossville-Woodrow' = 146, 'Rugby-Remsen Village' = 147, 'Schuylerville-Throgs Neck-Edgewater Park' = 148, 'Seagate-Coney Island' = 149, 'Sheepshead Bay-Gerritsen Beach-Manhattan Beach' = 150, 'SoHo-TriBeCa-Civic Center-Little Italy' = 151, 'Soundview-Bruckner' = 152, 'Soundview-Castle Hill-Clason Point-Harding Park' = 153, 'South Jamaica' = 154, 'South Ozone Park' = 155, 'Springfield Gardens North' = 156, 'Springfield Gardens South-Brookville' = 157, 'Spuyten Duyvil-Kingsbridge' = 158, 'St. Albans' = 159, 'Stapleton-Rosebank' = 160, 'Starrett City' = 161, 'Steinway' = 162, 'Stuyvesant Heights' = 163, 'Stuyvesant Town-Cooper Village' = 164, 'Sunset Park East' = 165, 'Sunset Park West' = 166, 'Todt Hill-Emerson Hill-Heartland Village-Lighthouse Hill' = 167, 'Turtle Bay-East Midtown' = 168, 'University Heights-Morris Heights' = 169, 'Upper East Side-Carnegie Hill' = 170, 'Upper West Side' = 171, 'Van Cortlandt Village' = 172, 'Van Nest-Morris Park-Westchester Square' = 173, 'Washington Heights North' = 174, 'Washington Heights South' = 175, 'West Brighton' = 176, 'West Concourse' = 177, 'West Farms-Bronx River' = 178, 'West New Brighton-New Brighton-St. George' = 179, 'West Village' = 180, 'Westchester-Unionport' = 181, 'Westerleigh' = 182, 'Whitestone' = 183, 'Williamsbridge-Olinville' = 184, 'Williamsburg' = 185, 'Windsor Terrace' = 186, 'Woodhaven' = 187, 'Woodlawn-Wakefield' = 188, 'Woodside' = 189, 'Yorkville' = 190, 'park-cemetery-etc-Bronx' = 191, 'park-cemetery-etc-Brooklyn' = 192, 'park-cemetery-etc-Manhattan' = 193, 'park-cemetery-etc-Queens' = 194, 'park-cemetery-etc-Staten Island' = 195)) AS dropoff_ntaname,
toUInt16(ifNull(dropoff_puma, '0')) AS dropoff_puma
FROM trips
Query performance Benchmarking
Query 1:
SELECT cab_type, count(*) FROM trips_mergetree GROUP BY cab_type 0.163 seconds.
Query 2:
SELECT passenger_count, avg(total_amount) FROM trips_mergetree GROUP BY passenger_count 0.834 seconds.
Query 3:
SELECT passenger_count, toYear(pickup_date) AS year, count(*) FROM trips_mergetree GROUP BY passenger_count, year 1.813 seconds.
Query 4:
SELECT passenger_count, toYear(pickup_date) AS year, round(trip_distance) AS distance, count(*) FROM trips_mergetree GROUP BY passenger_count, year, distance ORDER BY year, count(*) DESC 2.157 seconds.
References
- https://github.com/MinervaDB/ClickHouse
- https://github.com/MinervaDB/MinervaDB-ClickHouse-MySQL-Data-Reader
- https://github.com/toddwschneider/nyc-taxi-data
- http://tech.marksblogg.com/billion-nyc-taxi-rides-redshift.html
- https://clickhouse.yandex/docs/en/

The post Benchmarking ClickHouse Performance on Amazon EC2 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Database Replication from MySQL to ClickHouse for High Performance WebScale Analytics appeared first on The WebScale Database Infrastructure Operations Experts.
]]>MySQL works great for Online Transaction Processing (OLTP) systems, MySQL performance degrades with analytical queries on very large database infrastructure, I agree you can optimize MySQL query performance with InnoDB compressions but why then combine OLTP and OLAP (Online Analytics Processing Systems) when you have columnar stores which can deliver high performance analytical queries more efficiently? I have seen several companies building dedicated MySQL servers for Analytics but over the period of time they end spending more money in fine tuning MySQL for Analytics with no significant improvements, There is no point in blaming MySQL for what it is not built for, MySQL / MariaDB is any day a bad choice for columnar analytics / big data solutions. Columnar database systems are best suited for handling large quantities of data: data stored in columns typically is easier to compress, it is also easier to access on per column basis – typically you ask for some data stored in a couple of columns – an ability to retrieve just those columns instead of reading all of the rows and filter out unneeded data makes the data accessed faster. So how can you combine the best of both ? Using MySQL purely for Transaction Processing Systems and Archiving MySQL Transactional Data for Data Analytics on a columnar store like ClickHouse, This post is about archiving and replicating data from MySQL to ClickHouse, you can continue reading from here.
Recommended Reading for ClickHouse:
- Why we recommend ClickHouse over many other columnar database systems ? https://minervadb.com/index.php/2018/03/06/why-we-recommend-clickhouse-over-many-other-columnar-database-systems/
- Benchmarking ClickHouse on my MacBook Pro (Super impressive performance) – https://minervadb.com/index.php/2018/01/23/benchmarking-clickhouse-2/
- ClickHouse GitHub – https://github.com/ClickHouse
- Altinity GitHub – https://github.com/Altinity
- What you should know about RAID to improve Database Systems Performance – https://minervadb.com/index.php/2019/08/04/raid-redundant-storage-for-database-reliability/
The post Database Replication from MySQL to ClickHouse for High Performance WebScale Analytics appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Why we recommend ClickHouse over many other columnar database systems ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Why we recommend ClickHouse over many other columnar database systems ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post MinervaDB Technology Partnership Program appeared first on The WebScale Database Infrastructure Operations Experts.
]]>☛ How we work with partners ?
- Actively participate in our partner Go-To-Market strategies and fill the gaps addressing the challenges in building web-scale database infrastructure operations using MySQL, MariaDB, Percona Server and ClickHouse .
- The partners can contact our consulting, support and remote DBA services teams for scoping database infrastructure operations services, pre-sales, strategic advisory services and technology account management .
- Unbiased technology consulting, support and remote DBA services – We are an vendor neutral and independent MySQL, MariaDB, Percona Server and ClickHouse consulting, support and training company with core expertise in performance, scalability and high availability .
- We work as an extended team of our partners so they can benefit both technically and strategically from our technology partnership program .
- Global presence to technically and strategically support the partners worldwide .
☛ MinervaDB Technical Expertise
- MySQL – MySQL (GA and Enterprise) ; InnoDB ; MySQL NDB Cluster ; InnoDB Cluster ; MySQL performance monitoring and trending.
- MariaDB – MariaDB Server ; MariaDB Backup ; MariaDB MaxScale ; MariaDB ColumnStore ; MariaDB Spider.
- Percona Server – Percona toolkit ; XtraBackup ; Percona XtraDB Cluster ; TokuDB.
- Building and troubleshooting web-scale database infrastructure operations using MyRocks / RocksDB.
- InnoDB / XtraDB – Performance optimization ; troubleshooting and data recovery services.
- Performance benchmarking – Measure response time, throughput and recommendations.
- Capacity planning and sizing – Building infrastructure for performance, scalability and reliability for database operations proactively.
- Performance health check, diagnostics and forensics – Monitor your database performance 24*7 and Proactively troubleshoot.
- Performance optimization and tuning – High performance MySQL, Maximum reliability of your database infrastructure operations.
- Designing optimal schema (logical and physical) – Size it right first time and build an optimal data lifecycle management system.
- SQL performance tuning – Measure SQL performance by response time and conservative SQL engineering practices.
- Disk I/O tuning – Distribute disk operations optimally across the storage layer and build archiving plan early / proactively.
- High availability and site reliability engineering – Self healing database infrastructure operations, auto-failover and cross-DC availability services.
- Galera Cluster operations and troubleshooting.
- Continuent Tungsten operations and troubleshooting.
- MySQL load balancing solutions using HAProxy, ProxySQL, MySQL Router.
- Data recovery services – Building robust disaster recovery solutions, zero data loss systems and multi-location backup retention.
- Sharding and horizontal partitioning solutions – Building scalable database infrastructure for planet-scale internet properties.
- Database clustering solutions – Grow your MySQL infrastructure horizontally for performance, scalability and availability.
- Scale-out and replication – Building maximum availability database infrastructure operations.
- Database security – Database firewall, transaction audit and secured data operations.
- Database upgrades and migration – Seamless upgrades and migration of database infrastructure on zero downtime.
- ClickHouse – ClickHouse consulting, support and training.
☛ Technology focus – Vendor neutral and independent
| Technology Focus | Tools and Technologies |
|---|---|
| Linux | Ubuntu, Debian, CentOS, Red Hat Linux, Oracle Linux and SUSE Linux. |
| MySQL | MySQL GA, MySQL Enterprise, InnoDB, MySQL Enterprise Backup, MySQL Cluster CGE, MySQL Enterprise Monitor, MySQL Utilities, MySQL Enterprise Audit, MySQL Enterprise Firewall and MySQL Router. |
| Percona | Percona Server for MySQL, XtraDB, TokuDB, RocksDB, Percona Toolkit, Percona XtraBackup and PMM(Percona Monitoring & Management). |
| MariaDB | MariaDB Server, RocksDB, MariaDB Galera Cluster, MariaDB Backup, MariaDB MaxScale and MariaDB ColumnStore. |
| PostgreSQL | PostgreSQL Performance Benchmarking, Capacity Planning / Sizing, PostgreSQL Performance Optimization, PostgreSQL High Availability / Database Reliability Engineering, PostgreSQL Upgrades / Migration and PostgreSQL Security |
| Cloud DBA Services | IaaS and DBaaS including: Oracle Cloud, Google CloudSQL, Amazon Aurora, AWS RDS®, EC2®, Microsoft Azure® and Rackspace® Cloud |
| Performance Monitoring and Trending Platforms | MySQL Enterprise Monitor, Icinga, Zabbix, Prometheus and Grafana. |
| High Availability, Scale-Out, Replication and Load Balancer | MySQL Group Replication, MySQL Cluster CGE, InnoDB Cluster, Galera Cluster, Percona XtraDB Cluster, MariaDB MaxScale, Continuent Tungsten Replicator, MHA (Master High Availability Manager and tools for MySQL), HAProxy, ProxySQL, MySQL Router and Vitess. |
| Columnar Database Systems | ClickHouse, MariaDB ColumnStore |
| DevOps. and Automation | Vagrant, Docker, Kubernetes, Jenkins, Ganglia, Chef, Puppet, Ansible, Consul, JIRA, Graylog and Grafana. |
☛ Partial list of customers – What we did for them ?
- BankBazaar – MariaDB consultative support and remote DBA services
- MIX – MySQL consulting and professional services
- AOL– Performance benchmarking, capacity planning & sizing, remote DBA services and site reliability engineering services.
- eBay– Remote DBA services, MySQL DevOps. & automation, on-call DBA support (24*7) and MySQL upgrades / migration.
- Forbes.com– Remote DBA services, architecting & building highly available MySQL infrastructure operations and consulting & professional services for MySQL.
- National Geographic– MySQL consulting & professional services, performance audit & optimization and MySQL upgrades.
- Apigee– MySQL support and remote DBA services.
- PayPal– MySQL consulting & professional services, MySQL performance audit & recommendations and MySQL SRE.
- Yahoo– MySQL consulting & professional services, on-call DBA services and MySQL emergency support.
- Priceline.com – consulting & professional services for MySQL & Percona Server for MySQL, Performance optimization & tuning and MySQL SRE.
- Freshdesk – MySQL performance audit & recommendation, MySQL scale-out & replication solutions and MySQL consultancy.
- OLA – MySQL consultative support.
- Flipkart – MySQL consulting & professional services and MySQL consultative support.
- Paytm– MySQL consultative support.
- PetSmart– MySQL consulting & professional services and MySQL consultative support.
- ESPN – Architected & deployed MySQL high availability solution and MySQL consulting & professional services.
- Mashable – MySQL consulting and professional services.
- Proteans – MySQL performance audit & optimization and MySQL consulting & professional services.
- Symphony Software – MySQL performance audit & recommendations, custom MySQL sharding solution and MySQL upgrades / migration.
- Yatra – MySQL consultative support.
- Justdial– MySQL consultative support.
- Victoria’s Secret– MySQL performance audit & recommendations and MySQL replication solutions.
- Airpush– MySQL remote DBA services and MySQL consultancy.
- Virsec – Remote DBA services and consulting & professional services .
- Go-Jek – Deployed MySQL high availability solution using Percona XtraDB Cluster, MySQL emergency support, performance optimization and consultative support.
- Midtrans – 24*7 MySQL remote DBA services, MySQL high availability & fault tolerance solution using Percona XtraDB Cluster & ProxySQL and MySQL consultative support.
- Bukalapak– MySQL consultative support.
- Sequoia Capital – MySQL professional services, remote DBA services & consultative support for Sequoia APAC and Southeast Asia portfolio companies.
- Housing.com – consultative support and professional services.
- Electronic Arts – MySQL consulting & professional services addressing performance and scalability.
- Adyen – MySQL consulting and professional services.
- Pinterest – MySQL consulting & professional services addressing performance and scalability.
☛ Customer testimonials
” Shiv is a expert in MySQL performance, He can fine tune MySQL performance at instance, application and infrastructure level in a shortest duration, I would love to hire him again “
David Hutton
Head of IT operations
National Geographic
” If it’s about MySQL performance and scalability, I will first call Shiv and He has helped us several times in building optimal, scalable and highly available MySQL infrastructure operations “
Mark Gray
IT Manager
Nike Technologies
” If you are building an highly reliable MySQL ecosystem, Hiring Shiv and his team will simplify your project. He is a guru to build an highly available and fault tolerant web property “
Kevin Thomson
Business Head – Media properties
AOL
” Shiv and his team built an custom MySQL high availability solution for us across data centers which enabled 24*7*365 availability of our business services. His Soultions are non vendor biased and cost efficient “
Keshav Patel
Group Manager – IT
Lastminute.com
” Thinking about outsourcing your DBA function ? Shiv is the guy who you should be talking to, He can build an highly reliable 24*7 remote DBA team for an fraction of cost to hiring a Sr. level resident DBA “
Brian Lewis
Lead Systems Engineer
Priceline.com
” The shortest notice emergency DBA support provider I have ever worked with, They are highly responsive and professional. If we suspect something going wrong with our database systems, The immediate action item is contact Shiv and his team”
Sherly Williams
Manager -Business Continuity
GAP Inc.
” We have contracted MinervaDB for 24*7 remote DBA services, They delivered MySQL maximum reliability and availability solutions ahead of the project schedule using 100% open source and free tools, saving considerably our IT budget. “
Simon Matthew
IT Manager – Media & Entertainment
Vodafone PLC
“Our database infrastructure operations was highly unreliable till we engaged Shiv Iyer and his globally distributed team of consultants, Now we have 24*7 access to expert DBA(s) for a fraction of cost to hiring a resident full-time DBA”
Kerry Jones
Head – IT Operations
The BestBuy Inc
The post MinervaDB Technology Partnership Program appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Join ClickHouse India Users Group appeared first on The WebScale Database Infrastructure Operations Experts.
]]>ClickHouse repositories and downloads
Github:
- https://github.com/Yandex/ClickHouse
- https://github.com/Yandex/clickhouse-jdbc
- https://github.com/Yandex/clickhouse-odbc
Server Packages:
- Debian/Ubuntu: http://repo.yandex.ru/clickhouse/
- RPMs: https://packagecloud.io/altinity/clickhouse
- Docker: https://hub.docker.com/r/yandex/clickhouse-server/
Client Packages:
- https://hub.docker.com/r/yandex/clickhouse-client/
- JDBC: https://mvnrepository.com/artifact/ru.yandex.clickhouse/clickhouse-jdbc
- ODBC: https://github.com/yandex/clickhouse-odbc/releases
The post Join ClickHouse India Users Group appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Benchmarking ClickHouse on my MacBook Pro appeared first on The WebScale Database Infrastructure Operations Experts.
]]>From their website, here is what the OnTime data covers:
Airline on-time data are reported each month to the U.S. Department of Transportation (DOT), Bureau of Transportation Statistics (BTS) by the 16 U.S. air carriers that have at least 1 percent of total domestic scheduled-service passenger revenues, plus two other carriers that report voluntarily. The data cover nonstop scheduled-service flights between points within the United States (including territories) as described in 14 CFR Part 234 of DOT’s regulations. Data are available since January 1995. The following statistics are available:
Summary Statistics – All and late flights (total number, average departure delay, average taxi-out and average scheduled departure) and late flights (total and percent of diverted and cancelled flights).
Origin Airport
Destination Airport
Origin and Destination Airport
Airline
Flight Number
Detailed Statistics – Departure and arrival statistics (scheduled departure time, actual departure time, scheduled elapse time, departure delay, wheels-off time and taxi-out time) by airport and airline; airborne time, cancellation and diversion by airport and airline.
Departures
Arrivals
Airborne Time
Cancellation
Diversion
Downloading the data
Data is actually available from October 1987 until today (they are a few months behind in entering the latest data). Their drop-down in their website ( https://www.transtats.bts.gov) however only goes back to 1995. Data comes in a .zip file for every month, so I downloaded few files. Here is the direct link to download the files:
root@CSQL:/home/shiv# wget http://www.transtats.bts.gov/Download/On_Time_On_Time_Performance_2013_5.zip URL transformed to HTTPS due to an HSTS policy --2018-01-23 18:01:08-- https://www.transtats.bts.gov/Download/On_Time_On_Time_Performance_2013_5.zip Resolving www.transtats.bts.gov (www.transtats.bts.gov)... 204.68.194.70 Connecting to www.transtats.bts.gov (www.transtats.bts.gov)|204.68.194.70|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 26562728 (25M) [application/x-zip-compressed] Saving to: 'On_Time_On_Time_Performance_2013_5.zip' On_Time_On_Time_Performance_201 100%[=======================================================>] 25.33M 207KB/s in 2m 16s 2018-01-23 18:03:25 (191 KB/s) - 'On_Time_On_Time_Performance_2013_5.zip' saved [26562728/26562728]
“ontime” table structure
desc ontime DESCRIBE TABLE ontime ┌─name─────────────────┬─type───────────┬─default_type─┬─default_expression─┐ │ Year │ UInt16 │ │ │ │ Quarter │ UInt8 │ │ │ │ Month │ UInt8 │ │ │ │ DayofMonth │ UInt8 │ │ │ │ DayOfWeek │ UInt8 │ │ │ │ FlightDate │ Date │ │ │ │ UniqueCarrier │ FixedString(7) │ │ │ │ AirlineID │ Int32 │ │ │ │ Carrier │ FixedString(2) │ │ │ │ TailNum │ String │ │ │ │ FlightNum │ String │ │ │ │ OriginAirportID │ Int32 │ │ │ │ OriginAirportSeqID │ Int32 │ │ │ │ OriginCityMarketID │ Int32 │ │ │ │ Origin │ FixedString(5) │ │ │ │ OriginCityName │ String │ │ │ │ OriginState │ FixedString(2) │ │ │ │ OriginStateFips │ String │ │ │ │ OriginStateName │ String │ │ │ │ OriginWac │ Int32 │ │ │ │ DestAirportID │ Int32 │ │ │ │ DestAirportSeqID │ Int32 │ │ │ │ DestCityMarketID │ Int32 │ │ │ │ Dest │ FixedString(5) │ │ │ │ DestCityName │ String │ │ │ │ DestState │ FixedString(2) │ │ │ │ DestStateFips │ String │ │ │ │ DestStateName │ String │ │ │ │ DestWac │ Int32 │ │ │ │ CRSDepTime │ Int32 │ │ │ │ DepTime │ Int32 │ │ │ │ DepDelay │ Int32 │ │ │ │ DepDelayMinutes │ Int32 │ │ │ │ DepDel15 │ Int32 │ │ │ │ DepartureDelayGroups │ String │ │ │ │ DepTimeBlk │ String │ │ │ │ TaxiOut │ Int32 │ │ │ │ WheelsOff │ Int32 │ │ │ │ WheelsOn │ Int32 │ │ │ │ TaxiIn │ Int32 │ │ │ │ CRSArrTime │ Int32 │ │ │ │ ArrTime │ Int32 │ │ │ │ ArrDelay │ Int32 │ │ │ │ ArrDelayMinutes │ Int32 │ │ │ │ ArrDel15 │ Int32 │ │ │ │ ArrivalDelayGroups │ Int32 │ │ │ │ ArrTimeBlk │ String │ │ │ │ Cancelled │ UInt8 │ │ │ │ CancellationCode │ FixedString(1) │ │ │ │ Diverted │ UInt8 │ │ │ │ CRSElapsedTime │ Int32 │ │ │ │ ActualElapsedTime │ Int32 │ │ │ │ AirTime │ Int32 │ │ │ │ Flights │ Int32 │ │ │ │ Distance │ Int32 │ │ │ │ DistanceGroup │ UInt8 │ │ │ │ CarrierDelay │ Int32 │ │ │ │ WeatherDelay │ Int32 │ │ │ │ NASDelay │ Int32 │ │ │ │ SecurityDelay │ Int32 │ │ │ │ LateAircraftDelay │ Int32 │ │ │ │ FirstDepTime │ String │ │ │ │ TotalAddGTime │ String │ │ │ │ LongestAddGTime │ String │ │ │ │ DivAirportLandings │ String │ │ │ │ DivReachedDest │ String │ │ │ │ DivActualElapsedTime │ String │ │ │ │ DivArrDelay │ String │ │ │ │ DivDistance │ String │ │ │ │ Div1Airport │ String │ │ │ │ Div1AirportID │ Int32 │ │ │ │ Div1AirportSeqID │ Int32 │ │ │ │ Div1WheelsOn │ String │ │ │ │ Div1TotalGTime │ String │ │ │ │ Div1LongestGTime │ String │ │ │ │ Div1WheelsOff │ String │ │ │ │ Div1TailNum │ String │ │ │ │ Div2Airport │ String │ │ │ │ Div2AirportID │ Int32 │ │ │ │ Div2AirportSeqID │ Int32 │ │ │ │ Div2WheelsOn │ String │ │ │ │ Div2TotalGTime │ String │ │ │ │ Div2LongestGTime │ String │ │ │ │ Div2WheelsOff │ String │ │ │ │ Div2TailNum │ String │ │ │ │ Div3Airport │ String │ │ │ │ Div3AirportID │ Int32 │ │ │ │ Div3AirportSeqID │ Int32 │ │ │ │ Div3WheelsOn │ String │ │ │ │ Div3TotalGTime │ String │ │ │ │ Div3LongestGTime │ String │ │ │ │ Div3WheelsOff │ String │ │ │ │ Div3TailNum │ String │ │ │ │ Div4Airport │ String │ │ │ │ Div4AirportID │ Int32 │ │ │ │ Div4AirportSeqID │ Int32 │ │ │ │ Div4WheelsOn │ String │ │ │ │ Div4TotalGTime │ String │ │ │ │ Div4LongestGTime │ String │ │ │ │ Div4WheelsOff │ String │ │ │ │ Div4TailNum │ String │ │ │ │ Div5Airport │ String │ │ │ │ Div5AirportID │ Int32 │ │ │ │ Div5AirportSeqID │ Int32 │ │ │ │ Div5WheelsOn │ String │ │ │ │ Div5TotalGTime │ String │ │ │ │ Div5LongestGTime │ String │ │ │ │ Div5WheelsOff │ String │ │ │ │ Div5TailNum │ String │ │ │ └──────────────────────┴────────────────┴──────────────┴────────────────────┘ 109 rows in set. Elapsed: 0.091 sec.
Load data to ClickHouse
root@CSQL:/home/shiv# for i in On_Time_On_Time_Performance_2013_5.zip; do echo $i; unzip -cq $i '*.csv' | sed 's/\.00//g' | clickhouse-client --query="INSERT INTO ontime FORMAT CSVWithNames"; done
I have loaded 2.5 million records only for this benchmarking (doing this on my MacBook VM)
select count(1) from ontime; SELECT count(1) FROM ontime ┌─count(1)─┐ │ 2530089 │ └──────────┘
Query performance
Query 1
select avg(c1) from (select Year, Month, count(*) as c1 from ontime group by Year, Month);
SELECT avg(c1) FROM ( SELECT Year, Month, count(*) AS c1 FROM ontime GROUP BY Year, Month ) ┌──avg(c1)─┐ │ 506017.8 │ └──────────┘ 1 rows in set. Elapsed: 0.094 sec. Processed 2.53 million rows, 7.59 MB (26.86 million rows/s., 80.57 MB/s.)
Query 2
The number of flights per day from the year 1980 to 2008
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE (Year >= 1980) AND (Year <= 2013) GROUP BY DayOfWeek ORDER BY c DESC ┌─DayOfWeek─┬──────c─┐ │ 3 │ 384020 │ │ 5 │ 381632 │ │ 1 │ 368063 │ │ 4 │ 365107 │ │ 2 │ 363124 │ │ 7 │ 362386 │ │ 6 │ 305757 │ └───────────┴────────┘ 7 rows in set. Elapsed: 0.035 sec. Processed 2.53 million rows, 7.59 MB (71.33 million rows/s., 213.99 MB/s.)
Query 3
The number of flights delayed by more than 10 minutes, grouped by the day of the week, for 1980-2014
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE (DepDelay > 10) AND (Year >= 1980) AND (Year <= 2014) GROUP BY DayOfWeek ORDER BY c DESC ┌─DayOfWeek─┬─────c─┐ │ 5 │ 82774 │ │ 1 │ 80595 │ │ 3 │ 78867 │ │ 4 │ 78455 │ │ 2 │ 73523 │ │ 7 │ 72340 │ │ 6 │ 54453 │ └───────────┴───────┘ 7 rows in set. Elapsed: 0.098 sec. Processed 2.53 million rows, 17.71 MB (25.79 million rows/s., 180.53 MB/s.)
Query 4
The number of delays by airport for 2000-2008
SELECT Origin, count(*) AS c FROM ontime WHERE (DepDelay > 10) AND (Year >= 1980) AND (Year <= 2014) GROUP BY Origin ORDER BY c DESC LIMIT 10 ┌─Origin──┬─────c─┐ │ ATL\0\0 │ 35945 │ │ ORD\0\0 │ 32616 │ │ DFW\0\0 │ 27470 │ │ DEN\0\0 │ 21119 │ │ LAX\0\0 │ 15454 │ │ IAH\0\0 │ 14651 │ │ DTW\0\0 │ 14040 │ │ SFO\0\0 │ 14018 │ │ EWR\0\0 │ 12524 │ │ PHX\0\0 │ 11718 │ └─────────┴───────┘ 10 rows in set. Elapsed: 0.087 sec. Processed 2.53 million rows, 27.83 MB (29.07 million rows/s., 319.73 MB/s.)
Query 5
The number of delays by carrier between 1980 – 2014
SELECT Carrier, c, c2, (c * 1000) / c2 AS c3 FROM ( SELECT Carrier, count(*) AS c FROM ontime WHERE (DepDelay > 10) AND (Year >= 1980) AND (Year <= 2014) GROUP BY Carrier ) ANY INNER JOIN ( SELECT Carrier, count(*) AS c2 FROM ontime WHERE (Year >= 1980) AND (Year <= 2014) GROUP BY Carrier ) USING (Carrier) ORDER BY c3 DESC ┌─Carrier─┬─────c─┬─────c2─┬─────────────────c3─┐ │ PI │ 12334 │ 39594 │ 311.5118452290751 │ │ EA │ 10679 │ 37632 │ 283.77444727891157 │ │ TW │ 6573 │ 23761 │ 276.62977147426454 │ │ WN │ 91808 │ 388242 │ 236.47106701490307 │ │ MQ │ 33623 │ 143640 │ 234.07825118351434 │ │ EV │ 32068 │ 140110 │ 228.8773106844622 │ │ VX │ 1166 │ 5128 │ 227.37909516380654 │ │ CO │ 21934 │ 98702 │ 222.22447366821342 │ │ F9 │ 5790 │ 26656 │ 217.21188475390156 │ │ AL │ 6634 │ 31663 │ 209.51899693648738 │ │ DL │ 58111 │ 277642 │ 209.30190677203018 │ │ OH │ 6888 │ 33223 │ 207.32624988712638 │ │ UA │ 36478 │ 176851 │ 206.26403017229194 │ │ FL │ 15847 │ 76950 │ 205.93892137751786 │ │ AA │ 47797 │ 232915 │ 205.21220187622094 │ │ B6 │ 13743 │ 67330 │ 204.11406505272538 │ │ NW │ 11219 │ 55516 │ 202.08588515022697 │ │ XE │ 17577 │ 87277 │ 201.3932651213951 │ │ 9E │ 16419 │ 89637 │ 183.17212758124435 │ │ PA │ 1079 │ 6080 │ 177.4671052631579 │ │ PS │ 2306 │ 13169 │ 175.10820867188093 │ │ OO │ 33745 │ 193333 │ 174.54340438517997 │ │ YV │ 10380 │ 60881 │ 170.49654243524253 │ │ US │ 17427 │ 132937 │ 131.09217147972348 │ │ HP │ 2024 │ 15583 │ 129.88513123275365 │ │ AS │ 5824 │ 52993 │ 109.90130771988753 │ │ HA │ 1534 │ 22644 │ 67.74421480303833 │ └─────────┴───────┴────────┴────────────────────┘ 27 rows in set. Elapsed: 0.154 sec. Processed 5.06 million rows, 30.36 MB (32.95 million rows/s., 197.70 MB/s.)
Query 6
Percentage of flights delayed for more than 10 minutes, by year
SELECT Year, c1 / c2 FROM ( SELECT Year, count(*) * 1000 AS c1 FROM ontime WHERE DepDelay > 10 GROUP BY Year ) ANY INNER JOIN ( SELECT Year, count(*) AS c2 FROM ontime GROUP BY Year ) USING (Year) ORDER BY Year ASC ┌─Year─┬─────divide(c1, c2)─┐ │ 1988 │ 233.08158828241218 │ │ 2009 │ 126.58476272716568 │ │ 2010 │ 227.19108136859793 │ │ 2013 │ 217.86337903405135 │ └──────┴────────────────────┘ 4 rows in set. Elapsed: 0.074 sec. Processed 5.06 million rows, 20.24 MB (68.61 million rows/s., 274.44 MB/s.)
Conclusion
I am very impressed with performance of ClickHouse in my MacBook VM , These tests are conducted on cold cache and no tweaking is done to the ClickHouse Server for performance
The post Benchmarking ClickHouse on my MacBook Pro appeared first on The WebScale Database Infrastructure Operations Experts.
]]>