The post Building Infrastructure for ClickHouse Performance appeared first on The WebScale Database Infrastructure Operations Experts.
]]>When you are building a very large Database System for analytics on ClickHouse you have to carefully build and operate infrastructure for performance and scalability. Is there any one magic wand to take care of the full-stack performance ? Unfortunately, the answer is no ! If you are not proactively monitoring and sizing the database infrastructure, you may be experiencing severe performance bottleneck or sometimes the total database outage causing serious revenue impact and all these may happen during the peak business hours or season, So where do we start planning for the infrastructure of ClickHouse operations ? As your ClickHouse database grows, the complexity of the queries also increases so we strongly advocate for investing in observability / monitoring infrastructure to troubleshoot more efficiently / proactively, We at MinervaDB use Grafana ( https://grafana.com/grafana/plugins/vertamedia-clickhouse-datasource ) to monitor ClickHouse Operations and record every performance counters from CPU, Network, Memory / RAM and Storage .This blog post is about knowing and monitoring the infrastructure component’s performance to build optimal ClickHouse operations.
Monitor for overheating CPUs
The overheating can damage processor and even motherboard, Closely monitor the systems if you are overclocking and it is exceeding 100C, please turn off the system. Most modern processors do reduce their clockspeed when they get warm to try and cool themselves, This will cause sudden degradation in the performance.
Monitor your current CPU speed:
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq
You can also use turbostat to monitor the CPU load:
sudo ./turbostat --quiet --hide sysfs,IRQ,SMI,CoreTmp,PkgTmp,GFX%rc6,GFXMHz,PkgWatt,CorWatt,GFXWatt Core CPU Avg_MHz Busy% Bzy_MHz TSC_MHz CPU%c1 CPU%c3 CPU%c6 CPU%c7 - - 488 90.71 3900 3498 12.50 0.00 0.00 74.98 0 0 5 0.13 3900 3498 99.87 0.00 0.00 0.00 0 4 3897 99.99 3900 3498 0.01 1 1 0 0.00 3856 3498 0.01 0.00 0.00 99.98 1 5 0 99.00 3861 3498 0.01 2 2 1 0.02 3889 3498 0.03 0.00 0.00 99.95 2 6 0 87.81 3863 3498 0.05 3 3 0 0.01 3869 3498 0.02 0.00 0.00 99.97 3 7 0 0.00 3878 3498 0.03 Core CPU Avg_MHz Busy% Bzy_MHz TSC_MHz CPU%c1 CPU%c3 CPU%c6 CPU%c7 - - 491 82.79 3900 3498 12.42 0.00 0.00 74.99 0 0 27 0.69 3900 3498 99.31 0.00 0.00 0.00 0 4 3898 99.99 3900 3498 0.01 1 1 0 0.00 3883 3498 0.01 0.00 0.00 99.99 1 5 0 0.00 3898 3498 56.61 2 2 0 0.01 3889 3498 0.02 0.00 0.00 99.98 2 6 0 0.00 3889 3498 0.02 3 3 0 0.00 3856 3498 0.01 0.00 0.00 99.99 3 7 0 0.00 3897 3498 0.01
Using PSENSOR to monitor hardware temperature
psensor is a graphical hardware temperature monitor for Linux.
It can monitor:
- the temperature of the motherboard and CPU sensors (using lm-sensors).
- the temperature of the NVidia GPUs (using XNVCtrl).
- the temperature of ATI/AMD GPUs (not enabled in official distribution repositories, see the instructions for enabling its support).
- the temperature of the Hard Disk Drives (using hddtemp or libatasmart).
- the rotation speed of the fans (using lm-sensors).
- the CPU usage (since 0.6.2.10 and using Gtop2).
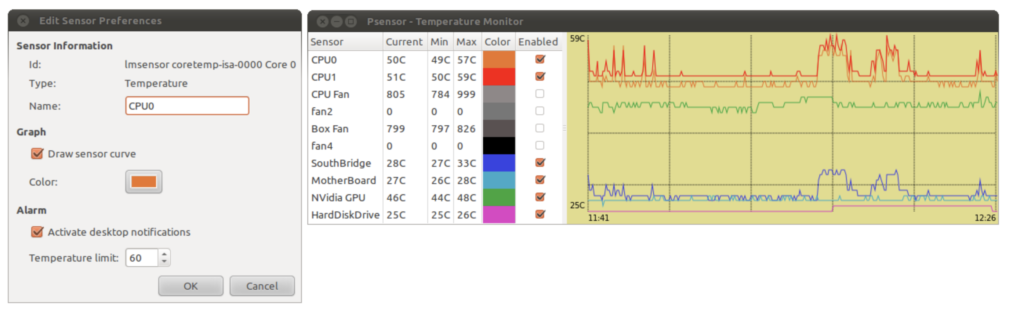
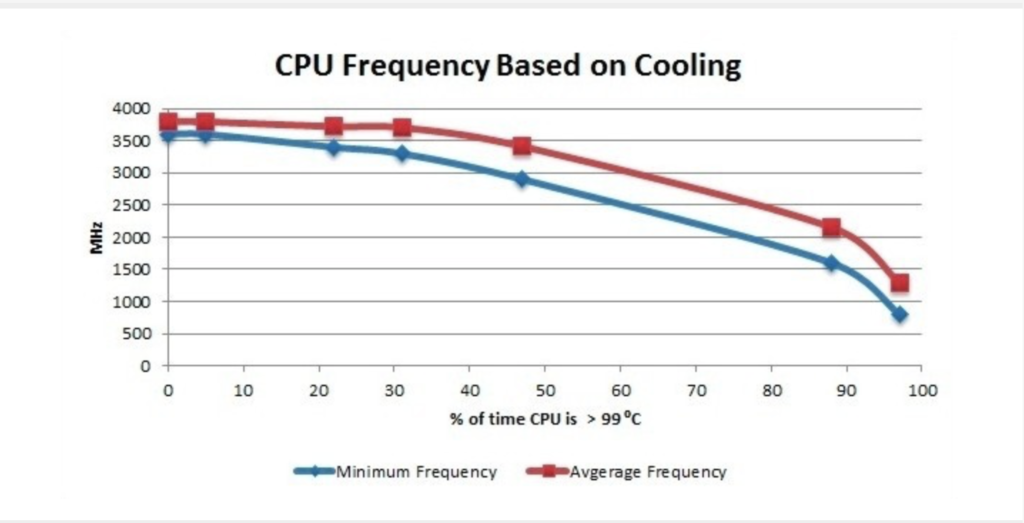
Since the Intel CPU thermal limit is 100 °C, we can quantify the amount of overheating by measuring the amount of time the CPU temperature was running at > 99 °C
Choosing RAID for Performance
The table below explains different RAID levels and how they impact on performance:
| RAID Level | Advantages | Disadvantages |
|---|---|---|
| RAID level 0 – Striping | RAID 0 offers great performance, both in read and write operations. There is no overhead caused by parity controls.RAID 0 offers great performance, both in read and write operations. All storage capacity is used, there is no overhead. | RAID 0 is not fault-tolerant. If one drive fails, all data in the RAID 0 array are lost. It should not be used for mission-critical systems. |
| RAID level 1 – Mirroring | RAID 1 offers excellent read speed and a write-speed that is comparable to that of a single drive. In case a drive fails, data do not have to be rebuild, they just have to be copied to the replacement drive. | Software RAID 1 solutions do not always allow a hot swap of a failed drive. That means the failed drive can only be replaced after powering down the computer it is attached to. For servers that are used simultaneously by many people, this may not be acceptable. Such systems typically use hardware controllers that do support hot swapping. The main disadvantage is that the effective storage capacity is only half of the total drive capacity because all data get written twice. |
| RAID level 5 | Read data transactions are very fast while write data transactions are somewhat slower (due to the parity that has to be calculated). If a drive fails, you still have access to all data, even while the failed drive is being replaced and the storage controller rebuilds the data on the new drive. | Technology complexity - If one of the disks in an array using 4TB disks fails and is replaced, restoring the data (the rebuild time) may take a day or longer, depending on the load on the array and the speed of the controller. If another disk goes bad during that time, data are lost forever. |
| RAID level 6 – Striping with double parity | READs are very fast, If two drives fail, you still have access to all data, even while the failed drives are being replaced. So RAID 6 is more secure than RAID 5. | Technology complexity - Rebuilding an array in which one drive failed can take a long time. Write data transactions are slower than RAID 5 due to the additional parity data that have to be calculated. In one report I read the write performance was 20% lower. |
| RAID level 10 – combining RAID 1 & RAID 0 | High Performance and Fault Tolerant - If something goes wrong, All we need to do is copying all the data from the surviving mirror to a new drive. | Highly expensive - Half of the storage capacity goes directly for mirroring. |
- Use NCQ with a long queue.
- Use CFQ scheduler for HDD.
- Enable write cache for improved WRITEs performance.
- Use noop for SSD.
- Ext4 is the most reliable.
You can read a detailed blog post about RAID here – https://minervadb.com/index.php/2019/08/04/raid-redundant-storage-for-database-reliability/
Huge Pages
What are Transparent Huge Pages and why they exist ? Operating Systems, Database Systems and several applications run in virtual memory. The Operating System manage virtual memory using pages (contiguous block of memory). Technically virtual memory is mapped to physical memory by the Operating System maintaining the page tables data structure in RAM. The address translation logic (page table walking) is implemented by the CPU’s memory management unit (MMU). The MMU also has a cache of recently used pages. This cache is called the Translation lookaside buffer (TLB).
Operating Systems manage virtual memory using pages (contiguous block of memory). Typically, the size of a memory page is 4 KB. 1 GB of memory is 256 000 pages; 128 GB is 32 768 000 pages. Obviously TLB cache can’t fit all of the pages and performance suffers from cache misses. There are two main ways to improve it. The first one is to increase TLB size, which is expensive and won’t help significantly. Another one is to increase the page size and therefore have less pages to map. Modern OSes and CPUs support large 2 MB and even 1 GB pages. Using large 2 MB pages, 128 GB of memory becomes just 64 000 pages.
Transparent Hugepage Support in Linux exist for performance. Transparent Huge Pages manages large pages automatically and transparently for applications. The benefits are pretty obvious: no changes required on application side; it reduces the number of TLB misses; page table walking becomes cheaper. The feature logically can be divided into two parts: allocation and maintenance. The THP takes the regular (“higher-order”) memory allocation path and it requires that the OS be able to find contiguous and aligned block of memory. It suffers from the same issues as the regular pages, namely fragmentation. If the OS can’t find a contiguous block of memory, it will try to compact, reclaim or page out other pages. That process is expensive and could cause latency spikes (up to seconds). This issue was addressed in the 4.6 kernel (via “defer” option), the OS falls back to a regular page if it can’t allocate a large one. The second part is maintenance. Even if an application touches just 1 byte of memory, it will consume whole 2 MB large page. This is obviously a waste of memory. So there’s a background kernel thread called “khugepaged”. It scans pages and tries to defragment and collapse them into one huge page. Despite it’s a background thread, it locks pages it works with, hence could cause latency spikes too. Another pitfall lays in large page splitting, not all parts of the OS work with large pages, e.g. swap. The OS splits large pages into regular ones for them. It could also degrade the performance and increase memory fragmentation.
Why we recommend to disable Transparent Huge Pages for ClickHouse Performance ?
Transparent Huge Pages (THP) is a Linux memory management system that reduces the overhead of Translation Lookaside Buffer (TLB) lookups on machines with large amounts of memory by using larger memory pages.
However, In our experience ClickHouse often perform poorly with THP enabled, because they tend to have sparse rather than contiguous memory access patterns. When running ClickHouse on Linux, THP should be disabled for best performance.
$ echo 'never' | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
Yandex recommends perf top to monitor the time spend in the kernel for memory management.
RAM
ClickHouse performs great with the high quality investments on RAM. As the data volumes increases, caching benefits more to the frequently executed SORT / SEARCH intensive analytical queries . “Yandex recommends you not to disable overcommit”. The value cat /proc/sys/vm/overcommit_memory should be 0 or 1. Run
$ echo 0 | sudo tee /proc/sys/vm/overcommit_memory
Conclusion
The visibility to ClickHouse Ops. is very important to build optimal, scalable and highly available Data Analytics platforms, Most often what happens is we measure the hardware infrastructure when there is a performance bottleneck and the reactive approach to troubleshoot performance is really expensive. When we work with our customers, we plan and conduct regular performance audits of their ClickHouse Ops. for right sizing their infrastructure.
References:
- https://alexandrnikitin.github.io/
- https://blogs.intel.com
- https://www.kernel.org/doc/Documentation/vm/transhuge.txt
- https://clickhouse.yandex/docs/en/
The post Building Infrastructure for ClickHouse Performance appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Benchmarking ClickHouse Performance on Amazon EC2 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>Amazon EC2 infrastructure used for benchmarking ClickHouse:
- Amazon EC2 instance details – R5DN Eight Extra Large / r5dn.8xlarge
- RAM – 256.0 GiB
- vCPUs – 32
- Storage – 1200 GiB (2 * 600 GiB NVMe SSD)
- Network performance – 25 Gigabit
Benchmarking Dataset – New York Taxi data
Data source :
https://github.com/toddwschneider/nyc-taxi-data
http://tech.marksblogg.com/billion-nyc-taxi-rides-redshift.html
You can either import raw data (from above sources  ) or download prepared partitions
) or download prepared partitions
Downloading the prepared partitions
$ curl -O https://clickhouse-datasets.s3.yandex.net/trips_mergetree/partitions/trips_mergetree.tar $ tar xvf trips_mergetree.tar -C /var/lib/clickhouse # path to ClickHouse data directory $ # check permissions of unpacked data, fix if required $ sudo service clickhouse-server restart $ clickhouse-client --query "select count(*) from datasets.trips_mergetree"
The entire download will be an uncompressed CSV data files of 227 GB in size, It takes approximately 50 minutes with 1Gbit of connection. The data must be pre-processed in PostgreSQL before loading to ClickHouse
$ time psql nyc-taxi-data -c "SELECT count(*) FROM trips;" ## Count 1299989791 (1 row) real 4m1.274s
Approx. 1.3 Billion records in PostgreSQL with database size of around 390 GB.
Exporting data from PostgreSQL:
COPY ( SELECT trips.id, trips.vendor_id, trips.pickup_datetime, trips.dropoff_datetime, trips.store_and_fwd_flag, trips.rate_code_id, trips.pickup_longitude, trips.pickup_latitude, trips.dropoff_longitude, trips.dropoff_latitude, trips.passenger_count, trips.trip_distance, trips.fare_amount, trips.extra, trips.mta_tax, trips.tip_amount, trips.tolls_amount, trips.ehail_fee, trips.improvement_surcharge, trips.total_amount, trips.payment_type, trips.trip_type, trips.pickup, trips.dropoff, cab_types.type cab_type, weather.precipitation_tenths_of_mm rain, weather.snow_depth_mm, weather.snowfall_mm, weather.max_temperature_tenths_degrees_celsius max_temp, weather.min_temperature_tenths_degrees_celsius min_temp, weather.average_wind_speed_tenths_of_meters_per_second wind, pick_up.gid pickup_nyct2010_gid, pick_up.ctlabel pickup_ctlabel, pick_up.borocode pickup_borocode, pick_up.boroname pickup_boroname, pick_up.ct2010 pickup_ct2010, pick_up.boroct2010 pickup_boroct2010, pick_up.cdeligibil pickup_cdeligibil, pick_up.ntacode pickup_ntacode, pick_up.ntaname pickup_ntaname, pick_up.puma pickup_puma, drop_off.gid dropoff_nyct2010_gid, drop_off.ctlabel dropoff_ctlabel, drop_off.borocode dropoff_borocode, drop_off.boroname dropoff_boroname, drop_off.ct2010 dropoff_ct2010, drop_off.boroct2010 dropoff_boroct2010, drop_off.cdeligibil dropoff_cdeligibil, drop_off.ntacode dropoff_ntacode, drop_off.ntaname dropoff_ntaname, drop_off.puma dropoff_puma FROM trips LEFT JOIN cab_types ON trips.cab_type_id = cab_types.id LEFT JOIN central_park_weather_observations_raw weather ON weather.date = trips.pickup_datetime::date LEFT JOIN nyct2010 pick_up ON pick_up.gid = trips.pickup_nyct2010_gid LEFT JOIN nyct2010 drop_off ON drop_off.gid = trips.dropoff_nyct2010_gid ) TO '/opt/milovidov/nyc-taxi-data/trips.tsv';
The entire activity will be completed in approx. 4 hours , the data snapshot speed was around 80MB per second and TSV file size is 590612904969 bytes.
For data cleansing and removing NULLs we will create a temporary table in ClickHouse:
CREATE TABLE trips ( trip_id UInt32, vendor_id String, pickup_datetime DateTime, dropoff_datetime Nullable(DateTime), store_and_fwd_flag Nullable(FixedString(1)), rate_code_id Nullable(UInt8), pickup_longitude Nullable(Float64), pickup_latitude Nullable(Float64), dropoff_longitude Nullable(Float64), dropoff_latitude Nullable(Float64), passenger_count Nullable(UInt8), trip_distance Nullable(Float64), fare_amount Nullable(Float32), extra Nullable(Float32), mta_tax Nullable(Float32), tip_amount Nullable(Float32), tolls_amount Nullable(Float32), ehail_fee Nullable(Float32), improvement_surcharge Nullable(Float32), total_amount Nullable(Float32), payment_type Nullable(String), trip_type Nullable(UInt8), pickup Nullable(String), dropoff Nullable(String), cab_type Nullable(String), precipitation Nullable(UInt8), snow_depth Nullable(UInt8), snowfall Nullable(UInt8), max_temperature Nullable(UInt8), min_temperature Nullable(UInt8), average_wind_speed Nullable(UInt8), pickup_nyct2010_gid Nullable(UInt8), pickup_ctlabel Nullable(String), pickup_borocode Nullable(UInt8), pickup_boroname Nullable(String), pickup_ct2010 Nullable(String), pickup_boroct2010 Nullable(String), pickup_cdeligibil Nullable(FixedString(1)), pickup_ntacode Nullable(String), pickup_ntaname Nullable(String), pickup_puma Nullable(String), dropoff_nyct2010_gid Nullable(UInt8), dropoff_ctlabel Nullable(String), dropoff_borocode Nullable(UInt8), dropoff_boroname Nullable(String), dropoff_ct2010 Nullable(String), dropoff_boroct2010 Nullable(String), dropoff_cdeligibil Nullable(String), dropoff_ntacode Nullable(String), dropoff_ntaname Nullable(String), dropoff_puma Nullable(String) ) ENGINE = Log;
$ time clickhouse-client --query="INSERT INTO trips FORMAT TabSeparated" < trips.tsv real 61m38.597s
I have done this benchmarking on a single ClickHouse server using MergeTree engine , Created Summary Table & loaded data below:
CREATE TABLE trips_mergetree
ENGINE = MergeTree(pickup_date, pickup_datetime, 8192)
AS SELECT
trip_id,
CAST(vendor_id AS Enum8('1' = 1, '2' = 2, 'CMT' = 3, 'VTS' = 4, 'DDS' = 5, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14)) AS vendor_id,
toDate(pickup_datetime) AS pickup_date,
ifNull(pickup_datetime, toDateTime(0)) AS pickup_datetime,
toDate(dropoff_datetime) AS dropoff_date,
ifNull(dropoff_datetime, toDateTime(0)) AS dropoff_datetime,
assumeNotNull(store_and_fwd_flag) IN ('Y', '1', '2') AS store_and_fwd_flag,
assumeNotNull(rate_code_id) AS rate_code_id,
assumeNotNull(pickup_longitude) AS pickup_longitude,
assumeNotNull(pickup_latitude) AS pickup_latitude,
assumeNotNull(dropoff_longitude) AS dropoff_longitude,
assumeNotNull(dropoff_latitude) AS dropoff_latitude,
assumeNotNull(passenger_count) AS passenger_count,
assumeNotNull(trip_distance) AS trip_distance,
assumeNotNull(fare_amount) AS fare_amount,
assumeNotNull(extra) AS extra,
assumeNotNull(mta_tax) AS mta_tax,
assumeNotNull(tip_amount) AS tip_amount,
assumeNotNull(tolls_amount) AS tolls_amount,
assumeNotNull(ehail_fee) AS ehail_fee,
assumeNotNull(improvement_surcharge) AS improvement_surcharge,
assumeNotNull(total_amount) AS total_amount,
CAST((assumeNotNull(payment_type) AS pt) IN ('CSH', 'CASH', 'Cash', 'CAS', 'Cas', '1') ? 'CSH' : (pt IN ('CRD', 'Credit', 'Cre', 'CRE', 'CREDIT', '2') ? 'CRE' : (pt IN ('NOC', 'No Charge', 'No', '3') ? 'NOC' : (pt IN ('DIS', 'Dispute', 'Dis', '4') ? 'DIS' : 'UNK'))) AS Enum8('CSH' = 1, 'CRE' = 2, 'UNK' = 0, 'NOC' = 3, 'DIS' = 4)) AS payment_type_,
assumeNotNull(trip_type) AS trip_type,
ifNull(toFixedString(unhex(pickup), 25), toFixedString('', 25)) AS pickup,
ifNull(toFixedString(unhex(dropoff), 25), toFixedString('', 25)) AS dropoff,
CAST(assumeNotNull(cab_type) AS Enum8('yellow' = 1, 'green' = 2, 'uber' = 3)) AS cab_type,
assumeNotNull(pickup_nyct2010_gid) AS pickup_nyct2010_gid,
toFloat32(ifNull(pickup_ctlabel, '0')) AS pickup_ctlabel,
assumeNotNull(pickup_borocode) AS pickup_borocode,
CAST(assumeNotNull(pickup_boroname) AS Enum8('Manhattan' = 1, 'Queens' = 4, 'Brooklyn' = 3, '' = 0, 'Bronx' = 2, 'Staten Island' = 5)) AS pickup_boroname,
toFixedString(ifNull(pickup_ct2010, '000000'), 6) AS pickup_ct2010,
toFixedString(ifNull(pickup_boroct2010, '0000000'), 7) AS pickup_boroct2010,
CAST(assumeNotNull(ifNull(pickup_cdeligibil, ' ')) AS Enum8(' ' = 0, 'E' = 1, 'I' = 2)) AS pickup_cdeligibil,
toFixedString(ifNull(pickup_ntacode, '0000'), 4) AS pickup_ntacode,
CAST(assumeNotNull(pickup_ntaname) AS Enum16('' = 0, 'Airport' = 1, 'Allerton-Pelham Gardens' = 2, 'Annadale-Huguenot-Prince\'s Bay-Eltingville' = 3, 'Arden Heights' = 4, 'Astoria' = 5, 'Auburndale' = 6, 'Baisley Park' = 7, 'Bath Beach' = 8, 'Battery Park City-Lower Manhattan' = 9, 'Bay Ridge' = 10, 'Bayside-Bayside Hills' = 11, 'Bedford' = 12, 'Bedford Park-Fordham North' = 13, 'Bellerose' = 14, 'Belmont' = 15, 'Bensonhurst East' = 16, 'Bensonhurst West' = 17, 'Borough Park' = 18, 'Breezy Point-Belle Harbor-Rockaway Park-Broad Channel' = 19, 'Briarwood-Jamaica Hills' = 20, 'Brighton Beach' = 21, 'Bronxdale' = 22, 'Brooklyn Heights-Cobble Hill' = 23, 'Brownsville' = 24, 'Bushwick North' = 25, 'Bushwick South' = 26, 'Cambria Heights' = 27, 'Canarsie' = 28, 'Carroll Gardens-Columbia Street-Red Hook' = 29, 'Central Harlem North-Polo Grounds' = 30, 'Central Harlem South' = 31, 'Charleston-Richmond Valley-Tottenville' = 32, 'Chinatown' = 33, 'Claremont-Bathgate' = 34, 'Clinton' = 35, 'Clinton Hill' = 36, 'Co-op City' = 37, 'College Point' = 38, 'Corona' = 39, 'Crotona Park East' = 40, 'Crown Heights North' = 41, 'Crown Heights South' = 42, 'Cypress Hills-City Line' = 43, 'DUMBO-Vinegar Hill-Downtown Brooklyn-Boerum Hill' = 44, 'Douglas Manor-Douglaston-Little Neck' = 45, 'Dyker Heights' = 46, 'East Concourse-Concourse Village' = 47, 'East Elmhurst' = 48, 'East Flatbush-Farragut' = 49, 'East Flushing' = 50, 'East Harlem North' = 51, 'East Harlem South' = 52, 'East New York' = 53, 'East New York (Pennsylvania Ave)' = 54, 'East Tremont' = 55, 'East Village' = 56, 'East Williamsburg' = 57, 'Eastchester-Edenwald-Baychester' = 58, 'Elmhurst' = 59, 'Elmhurst-Maspeth' = 60, 'Erasmus' = 61, 'Far Rockaway-Bayswater' = 62, 'Flatbush' = 63, 'Flatlands' = 64, 'Flushing' = 65, 'Fordham South' = 66, 'Forest Hills' = 67, 'Fort Greene' = 68, 'Fresh Meadows-Utopia' = 69, 'Ft. Totten-Bay Terrace-Clearview' = 70, 'Georgetown-Marine Park-Bergen Beach-Mill Basin' = 71, 'Glen Oaks-Floral Park-New Hyde Park' = 72, 'Glendale' = 73, 'Gramercy' = 74, 'Grasmere-Arrochar-Ft. Wadsworth' = 75, 'Gravesend' = 76, 'Great Kills' = 77, 'Greenpoint' = 78, 'Grymes Hill-Clifton-Fox Hills' = 79, 'Hamilton Heights' = 80, 'Hammels-Arverne-Edgemere' = 81, 'Highbridge' = 82, 'Hollis' = 83, 'Homecrest' = 84, 'Hudson Yards-Chelsea-Flatiron-Union Square' = 85, 'Hunters Point-Sunnyside-West Maspeth' = 86, 'Hunts Point' = 87, 'Jackson Heights' = 88, 'Jamaica' = 89, 'Jamaica Estates-Holliswood' = 90, 'Kensington-Ocean Parkway' = 91, 'Kew Gardens' = 92, 'Kew Gardens Hills' = 93, 'Kingsbridge Heights' = 94, 'Laurelton' = 95, 'Lenox Hill-Roosevelt Island' = 96, 'Lincoln Square' = 97, 'Lindenwood-Howard Beach' = 98, 'Longwood' = 99, 'Lower East Side' = 100, 'Madison' = 101, 'Manhattanville' = 102, 'Marble Hill-Inwood' = 103, 'Mariner\'s Harbor-Arlington-Port Ivory-Graniteville' = 104, 'Maspeth' = 105, 'Melrose South-Mott Haven North' = 106, 'Middle Village' = 107, 'Midtown-Midtown South' = 108, 'Midwood' = 109, 'Morningside Heights' = 110, 'Morrisania-Melrose' = 111, 'Mott Haven-Port Morris' = 112, 'Mount Hope' = 113, 'Murray Hill' = 114, 'Murray Hill-Kips Bay' = 115, 'New Brighton-Silver Lake' = 116, 'New Dorp-Midland Beach' = 117, 'New Springville-Bloomfield-Travis' = 118, 'North Corona' = 119, 'North Riverdale-Fieldston-Riverdale' = 120, 'North Side-South Side' = 121, 'Norwood' = 122, 'Oakland Gardens' = 123, 'Oakwood-Oakwood Beach' = 124, 'Ocean Hill' = 125, 'Ocean Parkway South' = 126, 'Old Astoria' = 127, 'Old Town-Dongan Hills-South Beach' = 128, 'Ozone Park' = 129, 'Park Slope-Gowanus' = 130, 'Parkchester' = 131, 'Pelham Bay-Country Club-City Island' = 132, 'Pelham Parkway' = 133, 'Pomonok-Flushing Heights-Hillcrest' = 134, 'Port Richmond' = 135, 'Prospect Heights' = 136, 'Prospect Lefferts Gardens-Wingate' = 137, 'Queens Village' = 138, 'Queensboro Hill' = 139, 'Queensbridge-Ravenswood-Long Island City' = 140, 'Rego Park' = 141, 'Richmond Hill' = 142, 'Ridgewood' = 143, 'Rikers Island' = 144, 'Rosedale' = 145, 'Rossville-Woodrow' = 146, 'Rugby-Remsen Village' = 147, 'Schuylerville-Throgs Neck-Edgewater Park' = 148, 'Seagate-Coney Island' = 149, 'Sheepshead Bay-Gerritsen Beach-Manhattan Beach' = 150, 'SoHo-TriBeCa-Civic Center-Little Italy' = 151, 'Soundview-Bruckner' = 152, 'Soundview-Castle Hill-Clason Point-Harding Park' = 153, 'South Jamaica' = 154, 'South Ozone Park' = 155, 'Springfield Gardens North' = 156, 'Springfield Gardens South-Brookville' = 157, 'Spuyten Duyvil-Kingsbridge' = 158, 'St. Albans' = 159, 'Stapleton-Rosebank' = 160, 'Starrett City' = 161, 'Steinway' = 162, 'Stuyvesant Heights' = 163, 'Stuyvesant Town-Cooper Village' = 164, 'Sunset Park East' = 165, 'Sunset Park West' = 166, 'Todt Hill-Emerson Hill-Heartland Village-Lighthouse Hill' = 167, 'Turtle Bay-East Midtown' = 168, 'University Heights-Morris Heights' = 169, 'Upper East Side-Carnegie Hill' = 170, 'Upper West Side' = 171, 'Van Cortlandt Village' = 172, 'Van Nest-Morris Park-Westchester Square' = 173, 'Washington Heights North' = 174, 'Washington Heights South' = 175, 'West Brighton' = 176, 'West Concourse' = 177, 'West Farms-Bronx River' = 178, 'West New Brighton-New Brighton-St. George' = 179, 'West Village' = 180, 'Westchester-Unionport' = 181, 'Westerleigh' = 182, 'Whitestone' = 183, 'Williamsbridge-Olinville' = 184, 'Williamsburg' = 185, 'Windsor Terrace' = 186, 'Woodhaven' = 187, 'Woodlawn-Wakefield' = 188, 'Woodside' = 189, 'Yorkville' = 190, 'park-cemetery-etc-Bronx' = 191, 'park-cemetery-etc-Brooklyn' = 192, 'park-cemetery-etc-Manhattan' = 193, 'park-cemetery-etc-Queens' = 194, 'park-cemetery-etc-Staten Island' = 195)) AS pickup_ntaname,
toUInt16(ifNull(pickup_puma, '0')) AS pickup_puma,
assumeNotNull(dropoff_nyct2010_gid) AS dropoff_nyct2010_gid,
toFloat32(ifNull(dropoff_ctlabel, '0')) AS dropoff_ctlabel,
assumeNotNull(dropoff_borocode) AS dropoff_borocode,
CAST(assumeNotNull(dropoff_boroname) AS Enum8('Manhattan' = 1, 'Queens' = 4, 'Brooklyn' = 3, '' = 0, 'Bronx' = 2, 'Staten Island' = 5)) AS dropoff_boroname,
toFixedString(ifNull(dropoff_ct2010, '000000'), 6) AS dropoff_ct2010,
toFixedString(ifNull(dropoff_boroct2010, '0000000'), 7) AS dropoff_boroct2010,
CAST(assumeNotNull(ifNull(dropoff_cdeligibil, ' ')) AS Enum8(' ' = 0, 'E' = 1, 'I' = 2)) AS dropoff_cdeligibil,
toFixedString(ifNull(dropoff_ntacode, '0000'), 4) AS dropoff_ntacode,
CAST(assumeNotNull(dropoff_ntaname) AS Enum16('' = 0, 'Airport' = 1, 'Allerton-Pelham Gardens' = 2, 'Annadale-Huguenot-Prince\'s Bay-Eltingville' = 3, 'Arden Heights' = 4, 'Astoria' = 5, 'Auburndale' = 6, 'Baisley Park' = 7, 'Bath Beach' = 8, 'Battery Park City-Lower Manhattan' = 9, 'Bay Ridge' = 10, 'Bayside-Bayside Hills' = 11, 'Bedford' = 12, 'Bedford Park-Fordham North' = 13, 'Bellerose' = 14, 'Belmont' = 15, 'Bensonhurst East' = 16, 'Bensonhurst West' = 17, 'Borough Park' = 18, 'Breezy Point-Belle Harbor-Rockaway Park-Broad Channel' = 19, 'Briarwood-Jamaica Hills' = 20, 'Brighton Beach' = 21, 'Bronxdale' = 22, 'Brooklyn Heights-Cobble Hill' = 23, 'Brownsville' = 24, 'Bushwick North' = 25, 'Bushwick South' = 26, 'Cambria Heights' = 27, 'Canarsie' = 28, 'Carroll Gardens-Columbia Street-Red Hook' = 29, 'Central Harlem North-Polo Grounds' = 30, 'Central Harlem South' = 31, 'Charleston-Richmond Valley-Tottenville' = 32, 'Chinatown' = 33, 'Claremont-Bathgate' = 34, 'Clinton' = 35, 'Clinton Hill' = 36, 'Co-op City' = 37, 'College Point' = 38, 'Corona' = 39, 'Crotona Park East' = 40, 'Crown Heights North' = 41, 'Crown Heights South' = 42, 'Cypress Hills-City Line' = 43, 'DUMBO-Vinegar Hill-Downtown Brooklyn-Boerum Hill' = 44, 'Douglas Manor-Douglaston-Little Neck' = 45, 'Dyker Heights' = 46, 'East Concourse-Concourse Village' = 47, 'East Elmhurst' = 48, 'East Flatbush-Farragut' = 49, 'East Flushing' = 50, 'East Harlem North' = 51, 'East Harlem South' = 52, 'East New York' = 53, 'East New York (Pennsylvania Ave)' = 54, 'East Tremont' = 55, 'East Village' = 56, 'East Williamsburg' = 57, 'Eastchester-Edenwald-Baychester' = 58, 'Elmhurst' = 59, 'Elmhurst-Maspeth' = 60, 'Erasmus' = 61, 'Far Rockaway-Bayswater' = 62, 'Flatbush' = 63, 'Flatlands' = 64, 'Flushing' = 65, 'Fordham South' = 66, 'Forest Hills' = 67, 'Fort Greene' = 68, 'Fresh Meadows-Utopia' = 69, 'Ft. Totten-Bay Terrace-Clearview' = 70, 'Georgetown-Marine Park-Bergen Beach-Mill Basin' = 71, 'Glen Oaks-Floral Park-New Hyde Park' = 72, 'Glendale' = 73, 'Gramercy' = 74, 'Grasmere-Arrochar-Ft. Wadsworth' = 75, 'Gravesend' = 76, 'Great Kills' = 77, 'Greenpoint' = 78, 'Grymes Hill-Clifton-Fox Hills' = 79, 'Hamilton Heights' = 80, 'Hammels-Arverne-Edgemere' = 81, 'Highbridge' = 82, 'Hollis' = 83, 'Homecrest' = 84, 'Hudson Yards-Chelsea-Flatiron-Union Square' = 85, 'Hunters Point-Sunnyside-West Maspeth' = 86, 'Hunts Point' = 87, 'Jackson Heights' = 88, 'Jamaica' = 89, 'Jamaica Estates-Holliswood' = 90, 'Kensington-Ocean Parkway' = 91, 'Kew Gardens' = 92, 'Kew Gardens Hills' = 93, 'Kingsbridge Heights' = 94, 'Laurelton' = 95, 'Lenox Hill-Roosevelt Island' = 96, 'Lincoln Square' = 97, 'Lindenwood-Howard Beach' = 98, 'Longwood' = 99, 'Lower East Side' = 100, 'Madison' = 101, 'Manhattanville' = 102, 'Marble Hill-Inwood' = 103, 'Mariner\'s Harbor-Arlington-Port Ivory-Graniteville' = 104, 'Maspeth' = 105, 'Melrose South-Mott Haven North' = 106, 'Middle Village' = 107, 'Midtown-Midtown South' = 108, 'Midwood' = 109, 'Morningside Heights' = 110, 'Morrisania-Melrose' = 111, 'Mott Haven-Port Morris' = 112, 'Mount Hope' = 113, 'Murray Hill' = 114, 'Murray Hill-Kips Bay' = 115, 'New Brighton-Silver Lake' = 116, 'New Dorp-Midland Beach' = 117, 'New Springville-Bloomfield-Travis' = 118, 'North Corona' = 119, 'North Riverdale-Fieldston-Riverdale' = 120, 'North Side-South Side' = 121, 'Norwood' = 122, 'Oakland Gardens' = 123, 'Oakwood-Oakwood Beach' = 124, 'Ocean Hill' = 125, 'Ocean Parkway South' = 126, 'Old Astoria' = 127, 'Old Town-Dongan Hills-South Beach' = 128, 'Ozone Park' = 129, 'Park Slope-Gowanus' = 130, 'Parkchester' = 131, 'Pelham Bay-Country Club-City Island' = 132, 'Pelham Parkway' = 133, 'Pomonok-Flushing Heights-Hillcrest' = 134, 'Port Richmond' = 135, 'Prospect Heights' = 136, 'Prospect Lefferts Gardens-Wingate' = 137, 'Queens Village' = 138, 'Queensboro Hill' = 139, 'Queensbridge-Ravenswood-Long Island City' = 140, 'Rego Park' = 141, 'Richmond Hill' = 142, 'Ridgewood' = 143, 'Rikers Island' = 144, 'Rosedale' = 145, 'Rossville-Woodrow' = 146, 'Rugby-Remsen Village' = 147, 'Schuylerville-Throgs Neck-Edgewater Park' = 148, 'Seagate-Coney Island' = 149, 'Sheepshead Bay-Gerritsen Beach-Manhattan Beach' = 150, 'SoHo-TriBeCa-Civic Center-Little Italy' = 151, 'Soundview-Bruckner' = 152, 'Soundview-Castle Hill-Clason Point-Harding Park' = 153, 'South Jamaica' = 154, 'South Ozone Park' = 155, 'Springfield Gardens North' = 156, 'Springfield Gardens South-Brookville' = 157, 'Spuyten Duyvil-Kingsbridge' = 158, 'St. Albans' = 159, 'Stapleton-Rosebank' = 160, 'Starrett City' = 161, 'Steinway' = 162, 'Stuyvesant Heights' = 163, 'Stuyvesant Town-Cooper Village' = 164, 'Sunset Park East' = 165, 'Sunset Park West' = 166, 'Todt Hill-Emerson Hill-Heartland Village-Lighthouse Hill' = 167, 'Turtle Bay-East Midtown' = 168, 'University Heights-Morris Heights' = 169, 'Upper East Side-Carnegie Hill' = 170, 'Upper West Side' = 171, 'Van Cortlandt Village' = 172, 'Van Nest-Morris Park-Westchester Square' = 173, 'Washington Heights North' = 174, 'Washington Heights South' = 175, 'West Brighton' = 176, 'West Concourse' = 177, 'West Farms-Bronx River' = 178, 'West New Brighton-New Brighton-St. George' = 179, 'West Village' = 180, 'Westchester-Unionport' = 181, 'Westerleigh' = 182, 'Whitestone' = 183, 'Williamsbridge-Olinville' = 184, 'Williamsburg' = 185, 'Windsor Terrace' = 186, 'Woodhaven' = 187, 'Woodlawn-Wakefield' = 188, 'Woodside' = 189, 'Yorkville' = 190, 'park-cemetery-etc-Bronx' = 191, 'park-cemetery-etc-Brooklyn' = 192, 'park-cemetery-etc-Manhattan' = 193, 'park-cemetery-etc-Queens' = 194, 'park-cemetery-etc-Staten Island' = 195)) AS dropoff_ntaname,
toUInt16(ifNull(dropoff_puma, '0')) AS dropoff_puma
FROM trips
Query performance Benchmarking
Query 1:
SELECT cab_type, count(*) FROM trips_mergetree GROUP BY cab_type 0.163 seconds.
Query 2:
SELECT passenger_count, avg(total_amount) FROM trips_mergetree GROUP BY passenger_count 0.834 seconds.
Query 3:
SELECT passenger_count, toYear(pickup_date) AS year, count(*) FROM trips_mergetree GROUP BY passenger_count, year 1.813 seconds.
Query 4:
SELECT passenger_count, toYear(pickup_date) AS year, round(trip_distance) AS distance, count(*) FROM trips_mergetree GROUP BY passenger_count, year, distance ORDER BY year, count(*) DESC 2.157 seconds.
References
- https://github.com/MinervaDB/ClickHouse
- https://github.com/MinervaDB/MinervaDB-ClickHouse-MySQL-Data-Reader
- https://github.com/toddwschneider/nyc-taxi-data
- http://tech.marksblogg.com/billion-nyc-taxi-rides-redshift.html
- https://clickhouse.yandex/docs/en/

The post Benchmarking ClickHouse Performance on Amazon EC2 appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Why we recommend ClickHouse over many other columnar database systems ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Why we recommend ClickHouse over many other columnar database systems ? appeared first on The WebScale Database Infrastructure Operations Experts.
]]>The post Join ClickHouse India Users Group appeared first on The WebScale Database Infrastructure Operations Experts.
]]>ClickHouse repositories and downloads
Github:
- https://github.com/Yandex/ClickHouse
- https://github.com/Yandex/clickhouse-jdbc
- https://github.com/Yandex/clickhouse-odbc
Server Packages:
- Debian/Ubuntu: http://repo.yandex.ru/clickhouse/
- RPMs: https://packagecloud.io/altinity/clickhouse
- Docker: https://hub.docker.com/r/yandex/clickhouse-server/
Client Packages:
- https://hub.docker.com/r/yandex/clickhouse-client/
- JDBC: https://mvnrepository.com/artifact/ru.yandex.clickhouse/clickhouse-jdbc
- ODBC: https://github.com/yandex/clickhouse-odbc/releases
The post Join ClickHouse India Users Group appeared first on The WebScale Database Infrastructure Operations Experts.
]]>