Table of Contents
Optimal Indexing for Performance – How to plan Index Ops. ?
An index or database index is a data structure which is used to quickly locate and access the data in a database table. Indexes are created on columns which will be the Search key that contains a copy of the primary key or candidate key of the table. These values are stored in sorted order so that the corresponding data can be accessed quickly (Note that the data may or may not be stored in sorted order). They are also Data Reference Pointers holding the address of the disk block where that particular key value can be found. Indexing in database systems is similar to what we see in books. There are complex design trade-offs involving lookup performance, index size, and index-update performance. Many index designs exhibit logarithmic (O(log(N))) lookup performance and in some applications it is possible to achieve flat (O(1)) performance. Indices can be implemented using a variety of data structures. Popular indices include balanced trees, B+ trees and hashes.The order that the index definition defines the columns in is important. It is possible to retrieve a set of row identifiers using only the first indexed column. However, it is not possible or efficient (on most databases) to retrieve the set of row identifiers using only the second or greater indexed column.
At a very high-level, There are only two kinds of Indexes:
- Ordered indices: Indices are based on a sorted ordering of the values.
- Hash indices: Indices are based on the values being distributed uniformly across a range of buckets. The buckets to which a value is assigned is determined by function called a hash function.
B+Tree indexing is a method of accessing and maintaining data. It should be used for large files that have unusual, unknown, or changing distributions because it reduces I/O processing when files are read. Also consider B+Tree indexing for files with long overflow chains. The prime block of the B+Tree index file (also called the root node) is pointed to by the header in the prime block of the B+Tree data file.
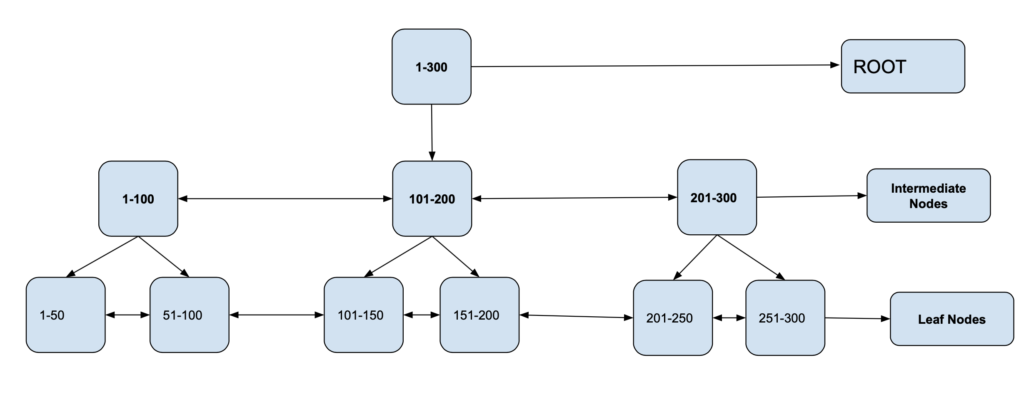
Indexing Attributes
Indexes are categorized on indexing attributes:
-
Primary Key Index
Primary Keys are unique and are stored in sorted manner, the performance of searching operation is quite efficient. The primary index is classified into two types : Dense Index and Sparse Index.
-
Dense Index
- For every search key value in the data file, there is an index record, This makes searching faster but requires more space to store index records itself.
- Index records contain search key value and a pointer to the actual record on the disk with that search key value.

-
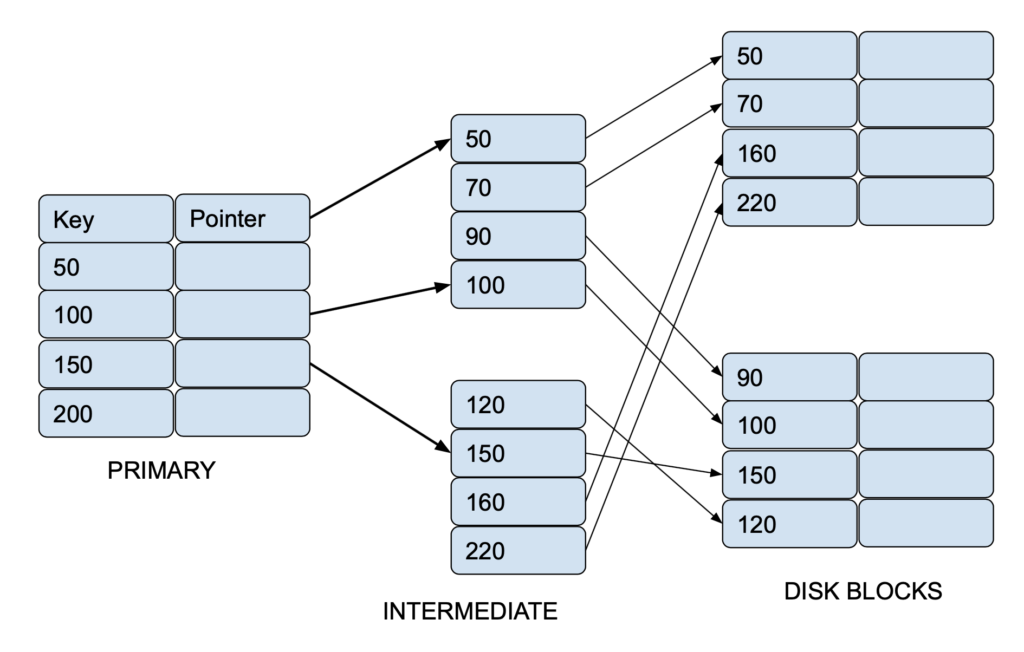
Sparse Index
- In Sparse Index, An index record here contains a search key and an actual pointer to the data on the disk. To search a record, we first proceed by index record and reach at the actual location of the data.
- Starts at that record pointed to by the index record, and proceed along the pointers in the file (that is, sequentially) until we find the desired record.
- If the data we are looking for is not where we directly reach by following the index, then the system starts sequential search until the desired data is found.
- Dense indices are faster in general, but sparse indices require less space and impose less maintenance for insertions and deletions so best suited for very large-scale high volume SORT / SEARCH queries
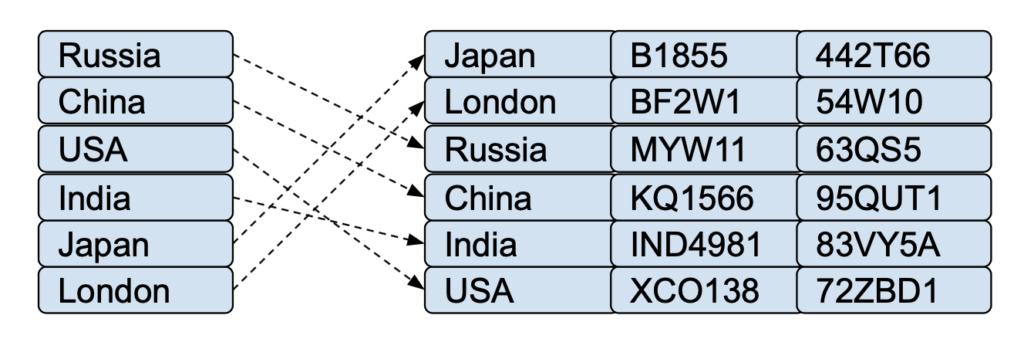
-
Secondary Index
- Secondary index may be generated from a field which is a candidate key and has a unique value in every record, or a non-key with duplicate values. Secondary indexes are on a non-primary key, which allows you to model one-to-many relationships. Secondary Index does not have any impact on how the rows are actually organized in data blocks. They can be in any order. The only ordering is w.r.t the index key in index blocks. Because secondary index does not have any control over the organization of rows, So there will be more I/O and thus queries can be less efficient with secondary index.
-
Clustered Index
- Clustered indexes sort and store the data rows in the table or view based on their key values. These are the columns included in the index definition. There can be only one clustered index per table, because the data rows themselves can be sorted in only one order. Clustered indexes are efficient on columns that are searched for a range of values. After the row with first value is found using a clustered index, rows with subsequent index values are guaranteed to be physically adjacent, thus providing faster access for a user query or an application. So the clustered index is about the way data is physically sorted on disk, which means it’s a good all-round choice for most situations.
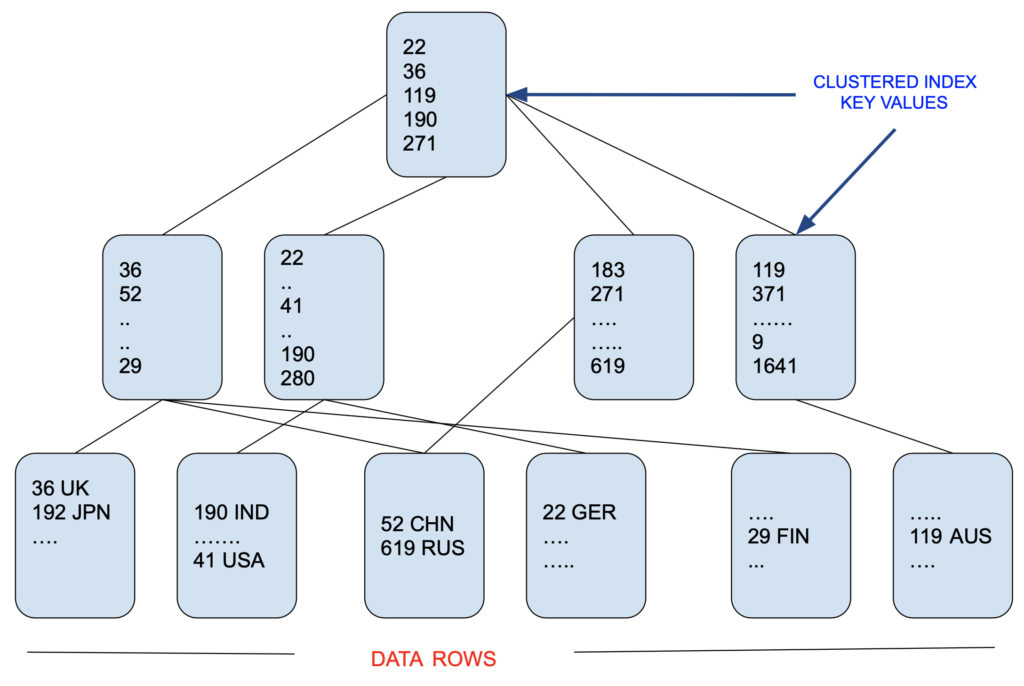
- Clustered indexes sort and store the data rows in the table or view based on their key values. These are the columns included in the index definition. There can be only one clustered index per table, because the data rows themselves can be sorted in only one order. Clustered indexes are efficient on columns that are searched for a range of values. After the row with first value is found using a clustered index, rows with subsequent index values are guaranteed to be physically adjacent, thus providing faster access for a user query or an application. So the clustered index is about the way data is physically sorted on disk, which means it’s a good all-round choice for most situations.
-
Non-Clustered Index
-
Nonclustered indexes have a structure separate from the data rows. A non-clustered index contains the non-clustered index key values and each key value entry has a pointer to the data row that contains the key value. The pointer from an index row in a non-clustered index to a data row is called a row locator. The structure of the row locator depends on whether the data pages are stored in a heap or a clustered table. For a heap, a row locator is a pointer to the row. For a clustered table, the row locator is the clustered index key. You can add non-key columns to the leaf level of the non-clustered index to by-pass existing index key limits, and execute fully covered, indexed, queries. The non-clustered index is created to improve the performance of frequently used queries not covered by clustered index. It’s like a textbook, the index page is created separately at the beginning of that book. When a query is issued against a column on which the index is created, the database will first go to the index and look for the address of the corresponding row in the table. It will then go to that row address and fetch other column values. It is due to this additional step that non-clustered indexes are slower than clustered indexes.
-
Why there is not standardization implemented for Index creation and operations management ?
There is no standard defines how to create indexes, because the ISO SQL Standard does not cover physical aspects. Indexes are one of the physical parts of database conception among others like storage (tablespace or filegroups). RDBMS vendors all give a CREATE INDEX syntax with some specific options that depend on their software’s capabilities.